Глупая причина, по которой не работает ваше хитрое приложение машинного зрения: ориентация в EXIF
5 мин
Перевод
Я много писал о проектах компьютерного зрения и машинного обучения, таких как системы распознавания объектов и проекты распознавания лиц. У меня также есть опенсорсная библиотека распознавания лиц на Python, которая как-то вошла в топ-10 самых популярных библиотек машинного обучения на Github. Всё это привело к тому, что новички в Python и машинном зрении задают мне много вопросов.
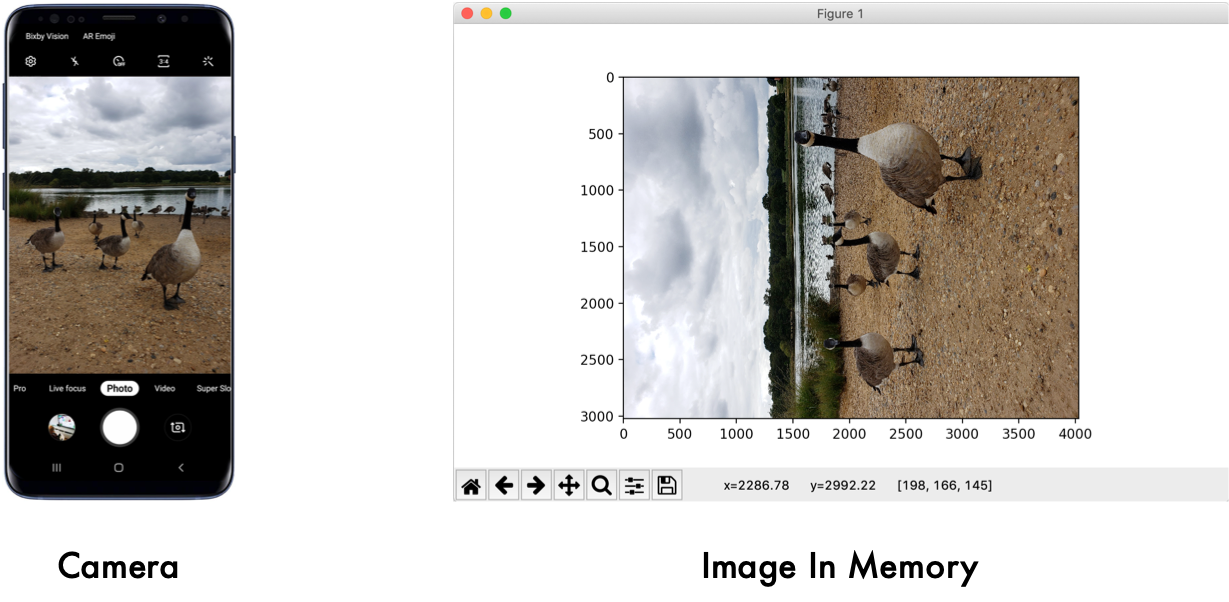
По опыту, есть одна конкретная техническая проблема, которая чаще всего ставит людей в тупик. Нет, это не сложный теоретический вопрос или проблема с дорогими GPU. Дело в том, что почти все загружают в память изображения повёрнутыми, даже не подозревая об этом. А компьютеры не очень хорошо обнаруживают объекты или распознают лица в повёрнутых изображениях.
По опыту, есть одна конкретная техническая проблема, которая чаще всего ставит людей в тупик. Нет, это не сложный теоретический вопрос или проблема с дорогими GPU. Дело в том, что почти все загружают в память изображения повёрнутыми, даже не подозревая об этом. А компьютеры не очень хорошо обнаруживают объекты или распознают лица в повёрнутых изображениях.