Хабрастатистика: анализируем комментарии читателей
4 мин
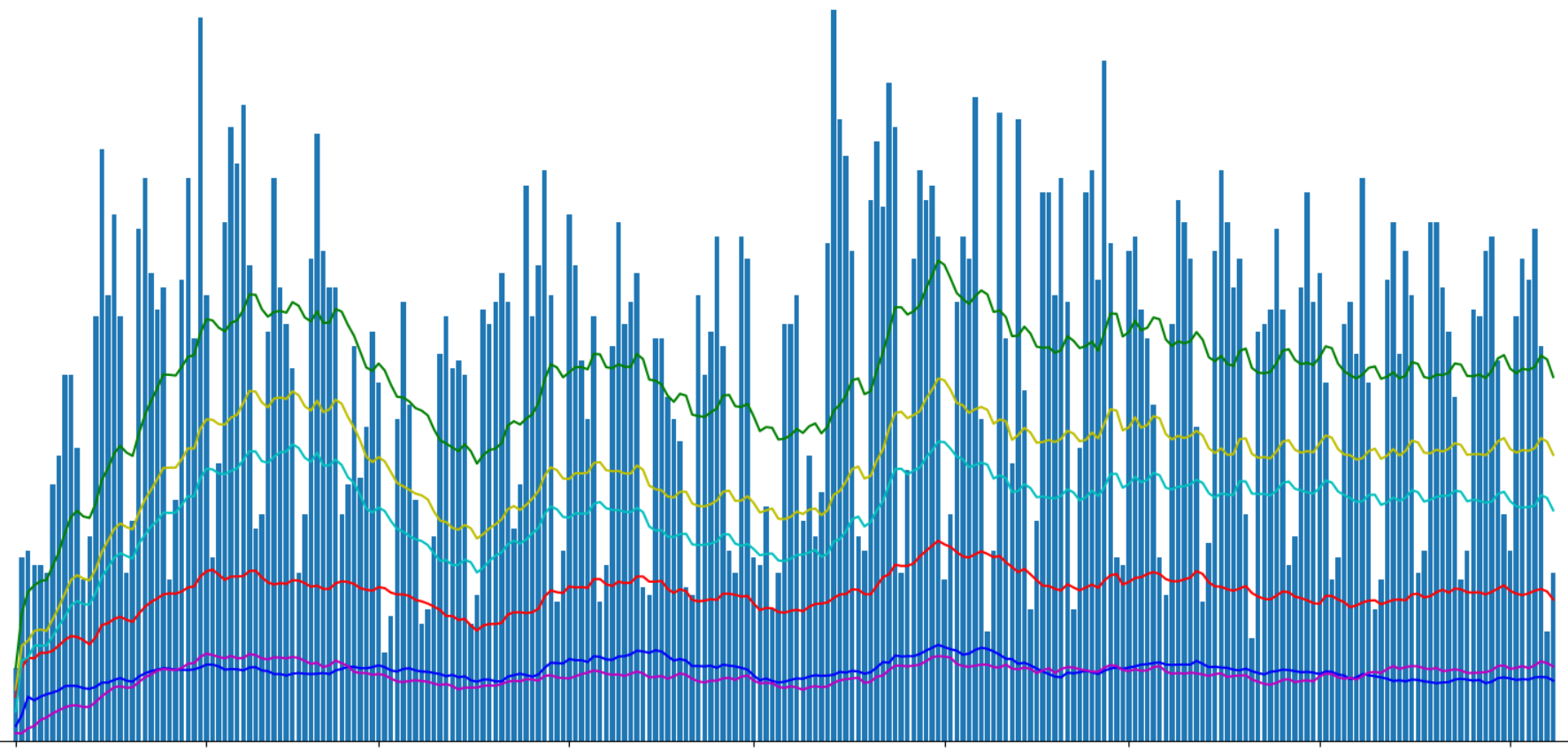
Привет Хабр. В предыдущей части была проанализирована популярность различных разделов сайта, и параллельно возник вопрос — какие данные можно извлечь из комментариев к статьям. Также хотелось проверить одну гипотезу, о которой скажу ниже.

Данные получились довольно интересные, также удалось составить небольшой «мини-рейтинг» комментаторов. Продолжение под катом.
Данные получились довольно интересные, также удалось составить небольшой «мини-рейтинг» комментаторов. Продолжение под катом.