Как устроен Domain-Driven Design
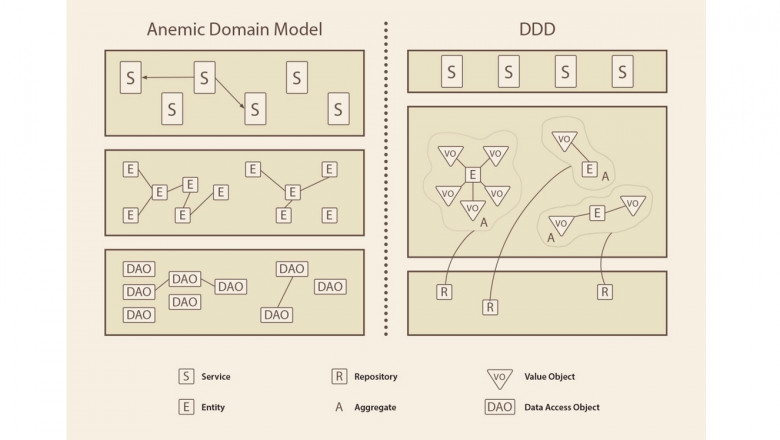
Многие проекты на Django начинаются просто: есть база данных и к приложению, которое крутится на сервере, идут обращения. Например, так начиналась Dodo IS (информационная система компании Додо Пицца, где работал автор сегодняшней статьи). Но если использовать Django из коробки, можно натворить много бед и встретить пачку антипаттернов. Возможно, вы встречали такое на старых legacy-проектах.
Евгений Пешков развивает сообщество DDD-практиков, рассказывая, какие проблемы решает Domain-Driven Design (предметно-ориентированное проектирование) в современном мире. На конференции Russian Python Week 2020 он выступил с рассказом об этом. Кстати, 19 августа пройдет встреча DDDevotion-сообщества, присоединяйтесь, будем о чем поговорить.
В сегодняшней статье будет его рассказ про то, как устроен Domain-Driven Design и какие инструменты использует, чтобы наиболее точно описать требования бизнеса и сам бизнес.