Примерно год назад Python Software Foundation
открыл Request for Information (RFI), чтобы обсудить, как можно обнаруживать загружаемые на PyPI вредоносные пакеты. Очевидно, что это реальная проблема, влияющая почти на любой менеджер пакетов: случаются
захваты имён заброшенных разработчиками пакетов,
эксплуатация опечаток в названиях популярных библиотек или
похищение пакетов при помощи упаковки учётных данных.
Реальность такова, что менеджеры пакетов наподобие PyPI являются критически важной инфраструктурой, которой пользуется почти любая компания. Я мог бы многое написать по этой теме, но сейчас достаточно будет этого выпуска xkcd.
Эта область знаний мне интересна, поэтому я ответил
своими мыслями о том, как мы можем подойти к решению проблемы. Весь пост стоит прочтения, но меня не оставляла в покое одна мысль: что происходит сразу же после установки пакета.
Такие действия, как установка сетевых соединений или исполнение команд во время процесса
pip install всегда стоит воспринимать настороженно, поскольку они не дают разработчику почти никакой возможности изучить код до того, как случится что-то плохое.
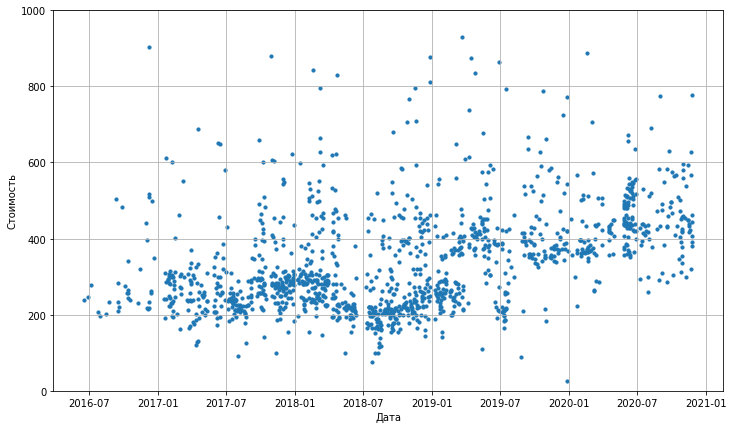
Я хотел глубже исследовать этот вопрос, поэтому в посте расскажу о том, как установил и проанализировал каждый пакет PyPI в поисках вредоносной активности.