Напишем и поймем Decision Tree на Python с нуля! Часть 1. Краткий обзор
8 мин
Перевод
Привет, Хабр! Представляю вашему вниманию перевод статьи "Pythonで0からディシジョンツリーを作って理解する (1. 概要編)".
Например, у нас есть следующий набор данных (дата сет): погода, температура, влажность, ветер, игра в гольф. В зависимости от погоды и остального, мы ходили (〇) или не ходили (×) играть в гольф. Предположим, что у нас есть 14 сложившихся вариантов.

Из этих данных мы можем составить структуру данных, показывающую, в каких случаях мы шли на гольф. Такая структура из-за своей ветвистой формы называется Decision Tree.
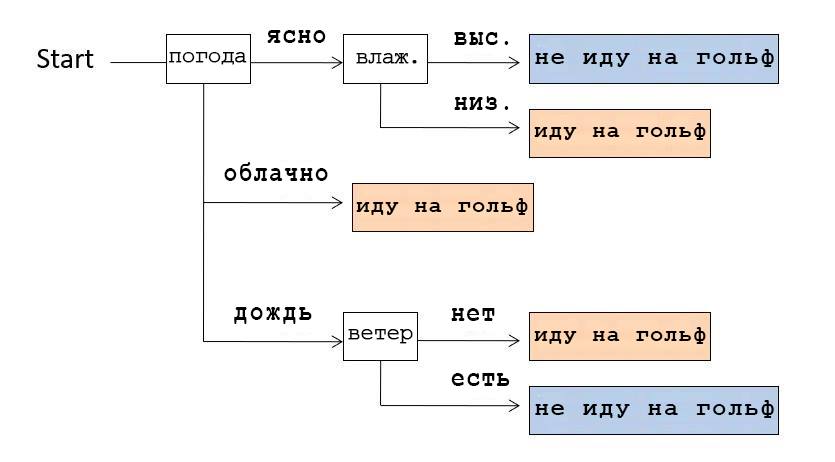
Например, если посмотреть на Decision Tree, изображенный на картинке выше, мы поймем, что сначала проверяли погоду. Если было ясно, мы проверяли влажность: если она высокая, то не шли играть в гольф, если низкая — шли. А если погода была облачная, то шли играть в гольф вне зависимости от других условий.
1.1 Что такое Decision Tree?
1.1.1 Пример Decision Tree
Например, у нас есть следующий набор данных (дата сет): погода, температура, влажность, ветер, игра в гольф. В зависимости от погоды и остального, мы ходили (〇) или не ходили (×) играть в гольф. Предположим, что у нас есть 14 сложившихся вариантов.
Из этих данных мы можем составить структуру данных, показывающую, в каких случаях мы шли на гольф. Такая структура из-за своей ветвистой формы называется Decision Tree.
Например, если посмотреть на Decision Tree, изображенный на картинке выше, мы поймем, что сначала проверяли погоду. Если было ясно, мы проверяли влажность: если она высокая, то не шли играть в гольф, если низкая — шли. А если погода была облачная, то шли играть в гольф вне зависимости от других условий.