

Александр Крижановский ( krizhanovsky, NatSys Lab.)
По Сети уже давно бегает эта картинка, по крайней мере, я ее часто видел на Фейсбуке, и появилась идея рассказать про нее:



 Добрый день, %username%. Меня зовут Антон Резников, я работаю над проектом Облако Mail.Ru Сегодня я хочу рассказать о технологиях балансировки трафика, проиллюстрировав историей о развитии социальной сети. Все персонажи выдуманы, а совпадения почти случайны. Статья обзорная, составлена по следам доклада на Highload Junior 2017. Некоторые вещи могут показаться элементарными, но опыт проведения собеседований показывает, что это не совсем так. Кое-что будет спорным, не без этого.
Добрый день, %username%. Меня зовут Антон Резников, я работаю над проектом Облако Mail.Ru Сегодня я хочу рассказать о технологиях балансировки трафика, проиллюстрировав историей о развитии социальной сети. Все персонажи выдуманы, а совпадения почти случайны. Статья обзорная, составлена по следам доклада на Highload Junior 2017. Некоторые вещи могут показаться элементарными, но опыт проведения собеседований показывает, что это не совсем так. Кое-что будет спорным, не без этого.Yandex Rate Limiter (далее просто YARL) — это сервис лимитирования нагрузки для распределённых сервисов. Его особенность в том, что он способен работать с миллионами квот, имея при этом очень низкие накладные расходы на проверку квоты. Если совсем кратко, это система распределённых Leaky Bucket'ов, с помощью которых можно ограничивать разные величины, связанные со временем: скорость передачи данных по сети, запросы в секунду и т. п.

Меня зовут Денис Кореневский, я работаю в службе разработки внутреннего хранилища Яндекса, и сегодня я расскажу, как YARL устроен внутри, почему мы вообще написали своё решение и с какими трудностями нам пришлось столкнуться в процессе создания. Добро пожаловать под кат.
Привет! Меня зовут Макс Матюхин, я работаю в SRV-команде Badoo. Мы в Badoo не только активно пишем посты в свой блог, но и внимательно читаем блоги наших коллег из других компаний. Недавно ребята из Dropbox опубликовали шикарный пост о различных способах оптимизации серверных приложений: начиная с железа и заканчивая уровнем приложения. Его автор – Алексей Иванов – дал огромное количество советов и ссылок на дополнительные источники информации. К сожалению, у Dropbox нет блога на Хабре, поэтому я решил перевести этот пост для наших читателей.
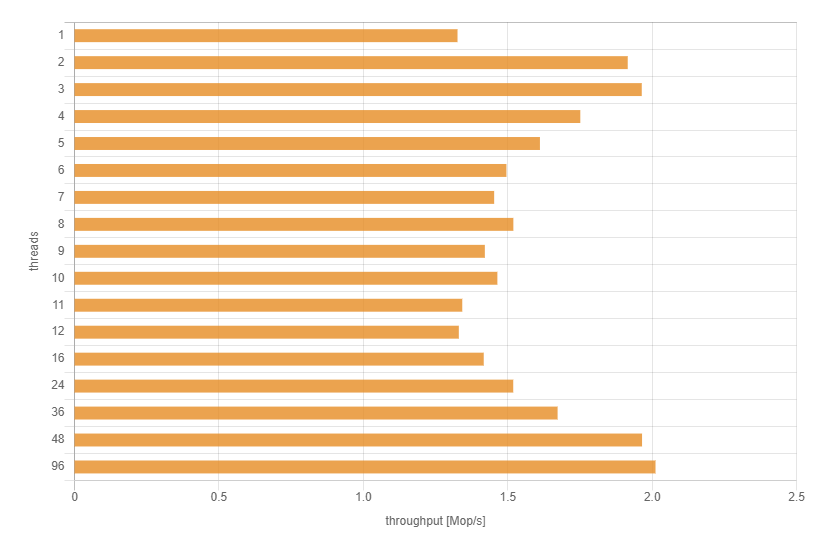
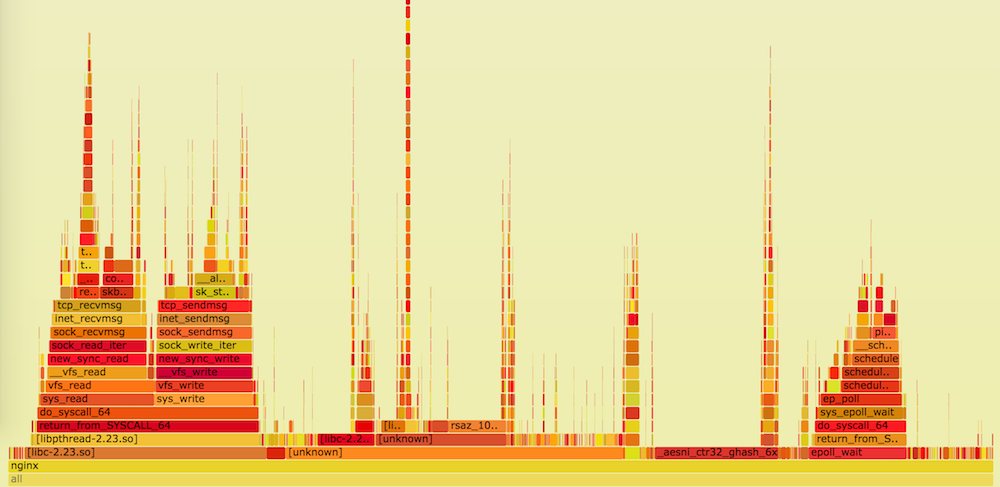
 Добрый день. Недавно меня заинтересовал модуль ngx_http_gzip_static_module, и я решил погонять мой домашний сервер немного с разными настройками сжатия nginx, чтобы убедится, действительно ли современные процессоры настолько быстрые, что можно ставить сжатие в 9-тку и не париться. В качестве подопытного файла выступала слитая главная страница lenta.ru – 170кб. Во время тестирования обнаружилась интересная особенность, которая изменила мои взгляды на выбор количества процессов nginx.
Добрый день. Недавно меня заинтересовал модуль ngx_http_gzip_static_module, и я решил погонять мой домашний сервер немного с разными настройками сжатия nginx, чтобы убедится, действительно ли современные процессоры настолько быстрые, что можно ставить сжатие в 9-тку и не париться. В качестве подопытного файла выступала слитая главная страница lenta.ru – 170кб. Во время тестирования обнаружилась интересная особенность, которая изменила мои взгляды на выбор количества процессов nginx.

Примечание: основная часть изложенного в статье относится к реализации SMT компании Intel, также называемой гипертредингом (hyper-threading). Она основана на научной статье компании, опубликованной в 2002 году.

Привет, я Никита Галушко, работаю над мессенджером ВКонтакте. Расскажу, как Go подходит к инлайнингу функций — этот процесс ещё называют встраиванием. В статье разберёмся, зачем вообще это нужно, какой профит можно получить для ускорения работы кода, а когда плюсы могут обернуться минусами. На примерах углубимся в специфику Go: как этот язык инлайнит функции, что можно и что нельзя встроить, какие возможности доступны в разных версиях. Также обсудим ограничения и способы обойти их.

Все говорили о микросервисах. Гибкость. Масштабируемость. Независимые команды. Звучало как мечта. Многие компании бросились распиливать свои монолиты. Разработка действительно ускорилась. Отдельные компоненты стало проще обновлять и разворачивать.
А потом сервисам понадобилось общаться. И мечта превратилась в сложную, многомерную головоломку.
Раз в несколько лет я устраиваю в нашей исследовательской группе челлендж «Напиши медленный код». Цель – написать код с минимально работоспособным количеством инструкций на цикл (IPC) с условием, чтобы этот код выполнялся на заранее подобранном сервере с архитектурой x86.
На первый взгляд, это абсурд В сущности, так и есть. Однако есть в этой безумной задаче и некоторая методическая ценность. Инженеры, проектирующие процессоры, прилагают все усилия ради достижения наивысшего возможного IPC… даже для очень неэффективного кода. Так и задумано, что писать код с очень высоким показателем IPC непросто. Следовательно, челлендж «Напиши медленный код» оказывается заковыристым упражнением, вынуждающим задумываться, как именно работает процессор, и как применить себе на пользу его острые углы.

Привет, Хабр!
Мы рассмотрим несколько примитивных настроек Linux, которые могут повысить производительность NVMe SSD дисков в разы. Под катом много интересных подробностей, так что скучно не будет.
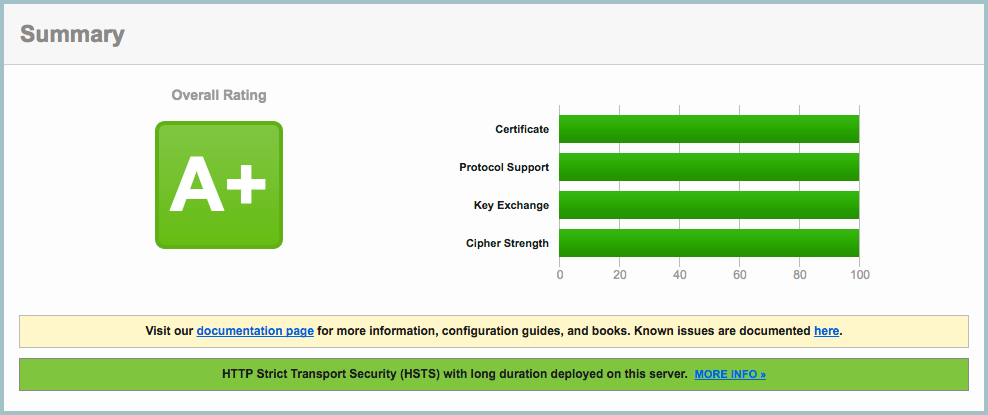
Много где написано о том, как получить 100% и A+ по тесту от Qualys. При всём при том практически везде директивы ssl_ciphers и подобные даются как эдакие магические строки, которые нужно просто вставить, и надеяться, что автор не подводит вас под монастырь. Эта статья призвана исправить это недоразумение. По прочтению этой статьи директива ssl_ciphers потеряет для вас всякую магию, а ECDHE и AES будут как друзья да братья.
Также вы узнаете почему 100% по тестам — не всегда хорошо в реальности.