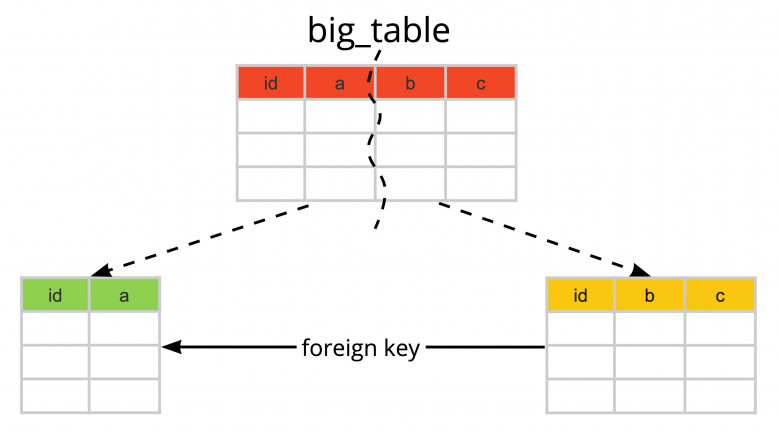
В процессе разработки витрин данных часто возникает задача предоставления клиентам данных в агрегированном виде. Если данных в хранилище немного, то их можно агрегировать “на лету”, но это плохая практика так как, чем больше будет копиться данных, тем дольше будут выполняться запросы, и тем больше Clickhouse будет съедать ресурсов. В этих случаях логично хранить данные в заранее агрегированном виде, вопрос лишь в том, как реализовать расчет данных агрегированных значений.
В интернете существуют много однотипных статей иллюстрирующих базовое использование материализованных представлений (далее - матвью) на движке AggregatingMergeTree, но если ваша задача выходит за рамки “1 нода, 1 метрика, 1 параметр агрегации” эти статьи вам мало чем помогут. Я посчитал, что моим коллегам может пригодиться своего рода гайд о том, как пользоваться данными представлениями для более сложных задач.
Гайд выполнен в виде шагов, иллюстрирующих мой путь в понимании данной концепции. Если я совершил какую-либо ошибку в процессе, и вы ее заметили, или у вас есть предложение по улучшению / дополнению данного гайда, прошу написать об этом в комментариях, уверен всем от этого будет только лучше.
В рамках моей задачи хранилище данных (далее - DWH) реализовано в виде реплицированного кластера состоящего из 3 нод, данные на ноды распределяются равномерно в соответствии с ключом сортировки таблиц. Существует исходная таблица source, которая содержит столбцы id, timecode_1, metric_data - данные представляют собой временной ряд утилизации ресурсов с гранулярностью 1 минута. Данные поступают блоками каждые 2 минуты.