Недавно у наших добрых друзей из крупной розничной сети возникла задача ускорения поиска в 1С.
Во-первых, искать нужно было по клиентам (три справочника, 9 текстовых полей, поиск типа %like%) и всего-то по 2,5 млн записей. Сразу скажем, что полнотекстовый поиск и морфология — это пока не про Tarantool. В результате ряда экспериментов мы остановились на ElasticSearch, но т.к. он не в тему статьи, то можем написать отдельную, если будет интерес. Скажем только, что скорость выросла на порядок по сравнению с тем, что мы могли выжать из полнотекстового поиска MS SQL.
Во-вторых, нужен был поиск и подбор по товарам с выводом остатков по всем складам без дополнительных запросов. Скорость поиска должна была быть сопоставима с обычным откликом интерфейса, то есть около 0,2 сек вместо текущих 5-12 секунд в 1С (в зависимости от уровня нагрузки). 90 тысяч строк, список номенклатур меняется не часто, примерно по 10-50 позиций в день.
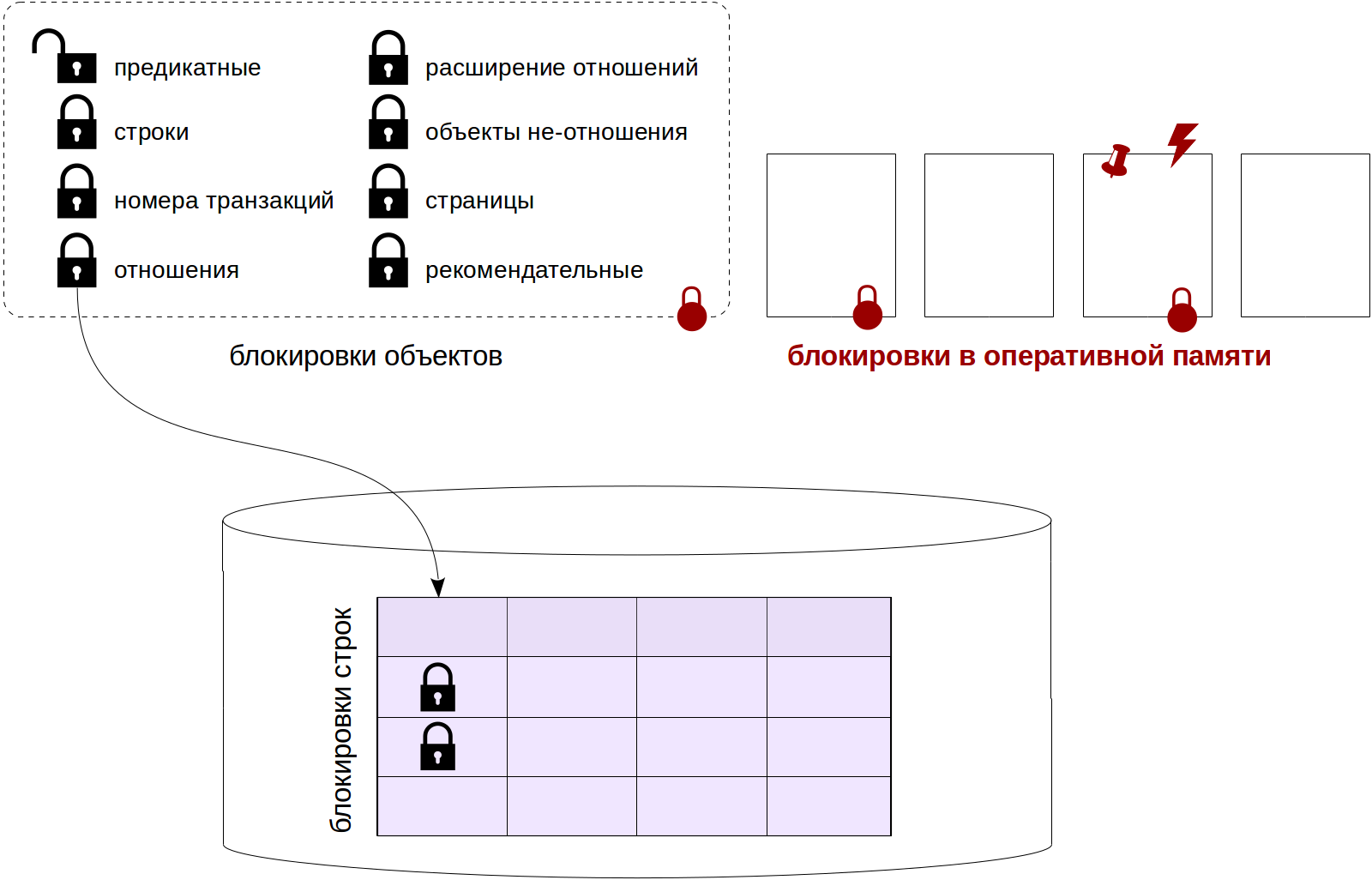
 Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж много. Поэтому каждый DBA (администратор базы данных), отвечающий за PostgreSQL, должен знать, как отслеживать потенциальные проблемы производительности, чтобы выяснить, что на самом деле происходит.
Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж много. Поэтому каждый DBA (администратор базы данных), отвечающий за PostgreSQL, должен знать, как отслеживать потенциальные проблемы производительности, чтобы выяснить, что на самом деле происходит.