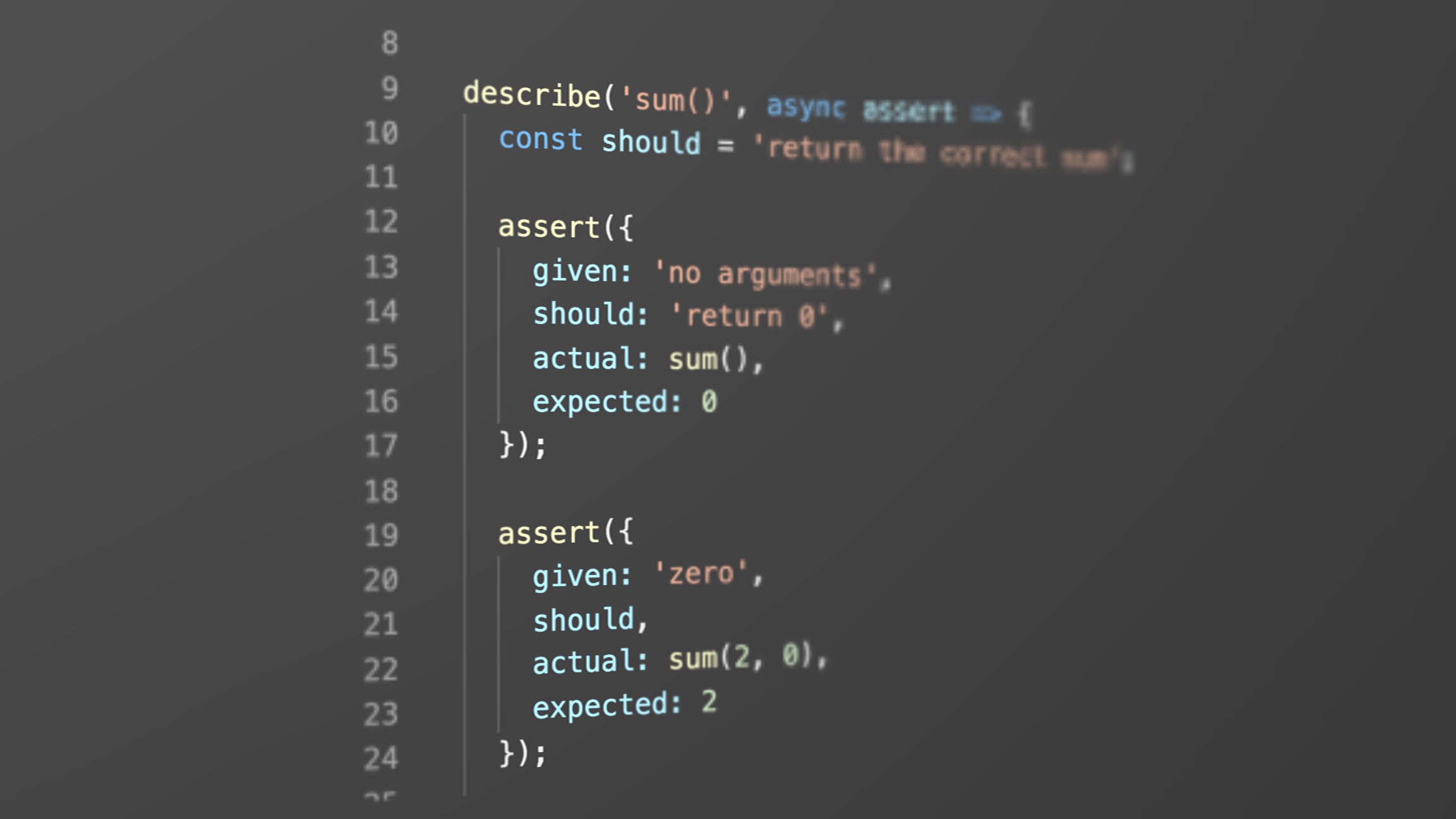
TDD, мокисты и реальные пацаны
2 мин
Рабочие обсуждения TDD и стратегий тестирования часто заходят в тупик.
Фаулер обтекаемо сказал, что это две культуры, мокисты против классиков.
Мокист: Давайте разрабатывать на моках.
— Это пустая трата времени! Их будет некому поддерживать и синхронизировать.
Мокист: Давайте напишем юнит-тесты.
— Полагаться на юнит-тесты опасно!
Мокист: Но если мы правильно разобъем компоненты…
— Да откуда вы уверены, что вы правильно разобъете?
Мокист: Давайте разобъем истории по юзер вэлью.
— Давайте! Но сначала нам нужно пофиксить упавший QA-энвайронмент.
Мокист: Тестировать на моках быстрее.
— Только интеграционные тесты на реальных зависимостях дадут нам ценную информацию! Да и кто ваши юнит-тесты будет поддерживать.
Мокист: Но интеграционные тесты долго выполняются и покрывают меньше сценариев.
— У меня на огромном проекте в прошлом все было прекрасно!
— Наши интеграционные тесты сломаны уже две недели. — Поставь skipTests и пропихни в QA, у нас деплоймент горит.
— Вы же обещали, что после релиза мы сможем отрефакторить лишние зависимости. — У нас продакшен инцидент, займись реальной работой.
Особенность этих обсуждений не в аргументах сторон, а скорее в манере ее ведения. Тут на кону нечто большее, чем разработка.
Можно предложить другой вариант: ботаники против реальных пацанов.
Фаулер обтекаемо сказал, что это две культуры, мокисты против классиков.
Мокист: Давайте разрабатывать на моках.
— Это пустая трата времени! Их будет некому поддерживать и синхронизировать.
Мокист: Давайте напишем юнит-тесты.
— Полагаться на юнит-тесты опасно!
Мокист: Но если мы правильно разобъем компоненты…
— Да откуда вы уверены, что вы правильно разобъете?
Мокист: Давайте разобъем истории по юзер вэлью.
— Давайте! Но сначала нам нужно пофиксить упавший QA-энвайронмент.
Мокист: Тестировать на моках быстрее.
— Только интеграционные тесты на реальных зависимостях дадут нам ценную информацию! Да и кто ваши юнит-тесты будет поддерживать.
Мокист: Но интеграционные тесты долго выполняются и покрывают меньше сценариев.
— У меня на огромном проекте в прошлом все было прекрасно!
— Наши интеграционные тесты сломаны уже две недели. — Поставь skipTests и пропихни в QA, у нас деплоймент горит.
— Вы же обещали, что после релиза мы сможем отрефакторить лишние зависимости. — У нас продакшен инцидент, займись реальной работой.
Особенность этих обсуждений не в аргументах сторон, а скорее в манере ее ведения. Тут на кону нечто большее, чем разработка.
Можно предложить другой вариант: ботаники против реальных пацанов.