Подборка статей о машинном обучении: кейсы, гайды и исследования за октябрь 2020
6 мин

В октябре традиционно в центре внимания вновь GPT-3. С моделью от OpenAI связано сразу несколько новостей — хорошая и не очень.
При работе с TensorFlowJS можно выделить три направления (рисунок 1):
1. использование обученных моделей без модификаций топологий и переобучений
2. использование предварительно обученную модель с возможной модификацией ее топологии или переобучении на базе новой тренировочной выборки данных, которая полностью соответствует решаемой вашей задачи.
3. создание и обучения моделей с нуля.






В предыдущих статьях, использовался только один из видов слоев нейронной сети – полносвязанные (dense, fully-connected), когда каждый нейрон исходного слоя имеет связь со всеми нейронами из предыдущих слоев.
Чтобы обработать, например, черно-белое изображение размером 24x24, мы должны были бы превратить матричное представление изображения в вектор, который содержит 24x24 элементов. Как можно вдуматься, с таким преобразованием мы теряем важный атрибут – взаимное расположение пикселей в вертикальном и горизонтальном направлении осей, а также, наверное, в большинстве случаев пиксел, находящийся в верхнем левом углу изображения вряд ли имеет какое-то логически объяснимое влияние друг на друга в большинстве случаев.
Для исключения этих недостатков – для обработки изображений используют сверточные слои (convolutional layer, CNN).
Основным назначением CNN является выделение из исходного изображения малых частей, содержащих опорные (характерные) признаки, такие как ребра, контуры, дуги или грани. На следующих уровнях обработки из этих ребер можно распознать более сложные повторяемые фрагменты текстур (окружности, квадратные фигуры и др.), которые дальше могут сложиться в еще более сложные текстуры (часть лица, колесо машины и др.).
Например, рассмотрим классическую задачу – распознавание изображения цифр. Каждая цифра имеет свой набор характерных для них фигур (окружности, линии). В тоже самое время каждую окружность или линию можно составить из более мелких ребер (рисунок 1)

В этой статье мы попробуем написать классификатор определяющий саркастические статьи используя машинное обучение и TensorFlow
Статья является переводом с Machine Learning Foundations: Part 10 — Using NLP to build a sarcasm classifier
В качестве обучающего набора данных используется датасет «Sarcasm in News Headlines» Ришаба Мишры. Это интересный набор данных, который собирает заголовки новостей из обычных источников новостей, а также еще несколько комедийных с поддельных новостных сайтов.
Набор данных представляет собой файл JSON с тремя столбцами.
is_sarcastic — 1, если запись саркастическая, иначе 0headline — заголовок статьиarticle_link — URL-адрес текста статьи
Привет, Хабр! Представляю вашему вниманию перевод статьи "Implementing RoI Pooling in TensorFlow + Keras" автора Jaime Sevilla.
В данный момент я прохожу курс машинного обучения. В учебном блоке "Компьютерное зрение" возникла необходимость в изучении RoI Pooling слоёв. Приведённая ниже статья мне показалась интересной, в связи с чем я решил поделиться переводом с сообществом.
В этом посте мы объясним основную концепцию и общее использование RoI pooling (Region of Interest — область интересов) и предоставим реализацию с использованием слоев Keras среды TensorFlow.



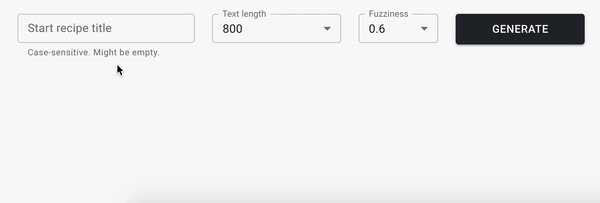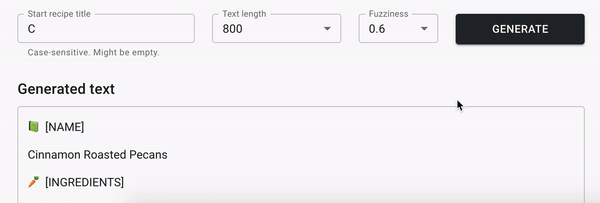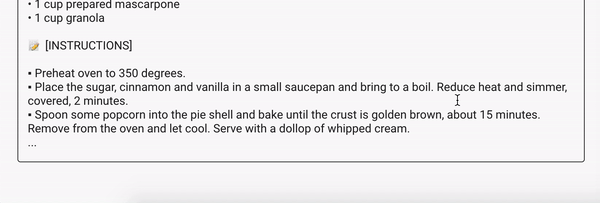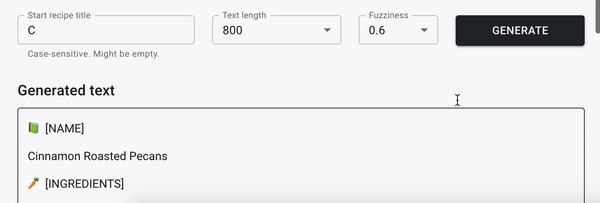
Я натренировал LSTM (Long short-term memory) рекуррентную нейронную сеть (RNN) на наборе данных, состоящих из ~100k рецептов, используя TensorFlow. В итоге нейронная сеть предложила мне приготовить "Сливочную соду с луком", "Клубничный суп из слоеного теста", "Чай со вкусом цукини" и "Лососевый мусс из говядины" .
Используя следующие ссылки вы сможете генерировать новые рецепты самостоятельно и найти детали тренировки модели:
В этой статье описаны детали тренировки LSTM модели на Python с использованием TensorFlow 2 и Keras API.