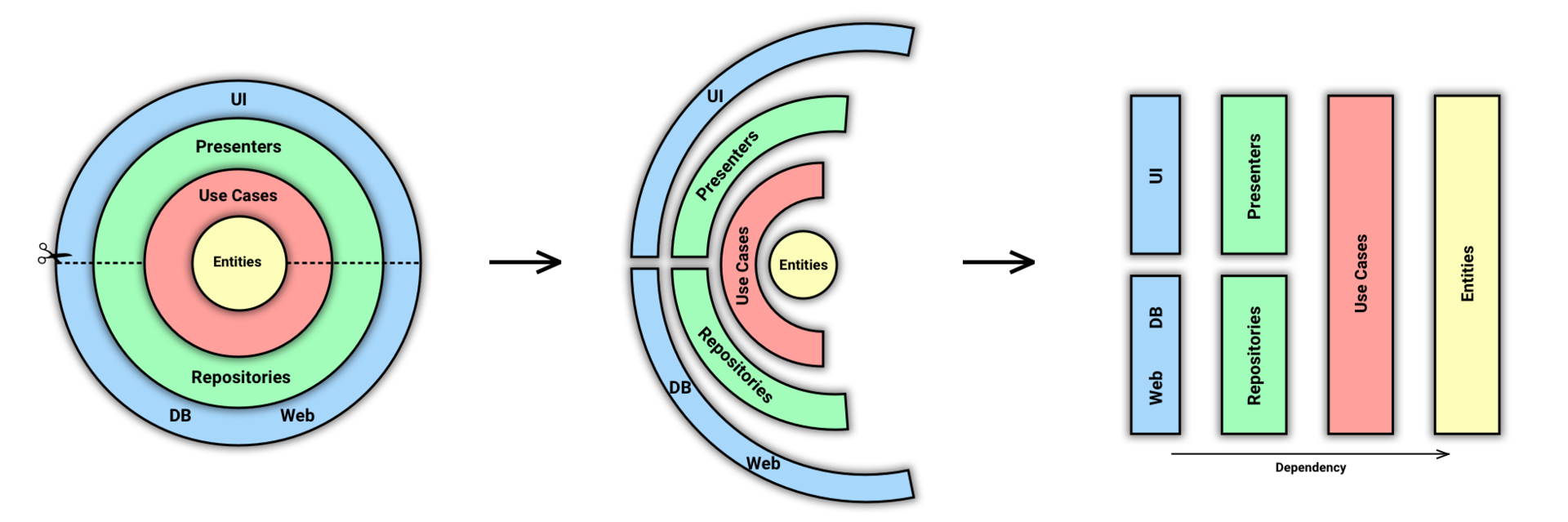
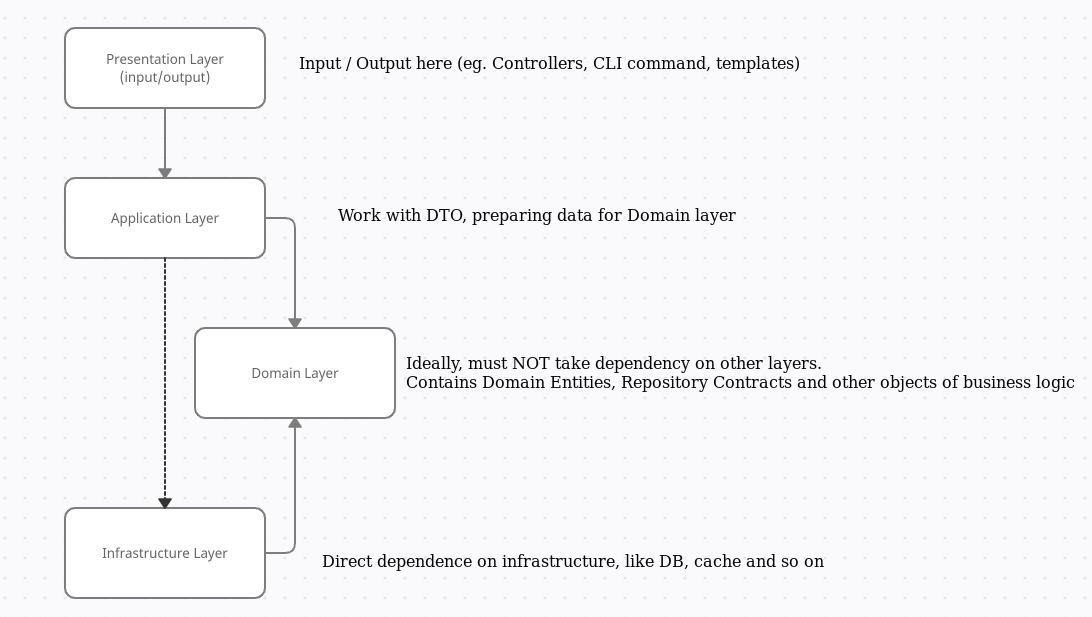
Есть несколько вещей, которыми можно заниматься вечно: смотреть на огонь, фиксить баги в легаси-коде и, конечно, говорить о DI — и всё равно нет-нет, да и будешь сталкиваться со странными зависимостями в очередном приложении.
В контексте языка GO, впрочем, ситуация чуть сложнее, поскольку явно выраженного и всеми поддерживаемого стандарта работы с зависимостями нет и каждый крутит педали своего собственного маленького самоката — а, значит, есть что обсудить и сравнить.
В данной статье я рассмотрю самые популярные инструменты и подходы для организации иерархии зависимостей в go, с их преимуществами и недостатками. В случае, если вы знаете теорию и аббревиатура DI не вызывает у вас вопросов (в том числе и необходимость применения этого подхода), то можете начинать читать статью с середины, в первую половине я объясню, что такое DI, зачем это нужно вообще и в частности в го.