В последнее время коптеры из игрушек и летающих камер становятся Большим Бизнесом. Коптеры доставляют грузы, делают съемку местности, охраняют периметр, распыляют химикаты в полях и даже красят, в общем выполняют разного рода задания. Разумеется большинство действий делаются не вручную, с пульта, а выполняются программно.

Иван Лобов @IvanLobov
Пользователь
Программирование на Python — курс для желающих узнать о нём больше или изучить ещё один язык программирования
3 мин
Туториал
"The joy of coding Python should be in seeing short, concise, readable classes that express a lot of action in a small amount of clear code — not in reams of trivial code that bores the reader to death."
Guido van Rossum
 Python — язык программирования, на котором приятно писать и который приятно читать. Мы предлагаем тринадцать лекций осеннего курса CS центра, чтобы посмотреть вглубь языка и попробовать понять, как пользоваться всеми его возможностями. Лекции читает Сергей Лебедев, разработчик в компании JetBrains и преподаватель в Computer Science Center.
Python — язык программирования, на котором приятно писать и который приятно читать. Мы предлагаем тринадцать лекций осеннего курса CS центра, чтобы посмотреть вглубь языка и попробовать понять, как пользоваться всеми его возможностями. Лекции читает Сергей Лебедев, разработчик в компании JetBrains и преподаватель в Computer Science Center. Мало освоить синтаксис, чтобы узнать язык программирования: нужно осознать идиомы языка и научиться их применять. В течение курса Сергей знакомит слушателей с идиомами и возможностями языка Python.
Фотография сделана осенью 2014 года в Страсбурге, за две недели до начала первого прочтения этого курса.
MCMC-сэмплинг для тех, кто учился, но ничего не понял
15 мин
Перевод
Рассказывая о вероятностном программировании и Байесовской статистике, я обычно не уделяю особого внимания тому, как, на самом деле, выполняется вероятностный вывод, рассматривая его как некий «чёрный ящик». Вся прелесть вероятностного программирования заключается в том, что, на самом деле, для того, чтобы строить модели, не обязательно понимать, как именно делается вывод. Но это знание, безусловно, весьма полезно.

Как-то раз я рассказывал о новой Байесовской модели человеку, который не особенно разбирался в предмете, но очень хотел всё понять. Он-то и спросил меня о том, чего я обычно не касаюсь. «Томас, — сказал он, — а как, на самом деле, выполняется вероятностный вывод? Как получаются эти таинственные сэмплы из апостериорной вероятности?».
Как-то раз я рассказывал о новой Байесовской модели человеку, который не особенно разбирался в предмете, но очень хотел всё понять. Он-то и спросил меня о том, чего я обычно не касаюсь. «Томас, — сказал он, — а как, на самом деле, выполняется вероятностный вывод? Как получаются эти таинственные сэмплы из апостериорной вероятности?».
Как можно упростить себе жизнь с помощью Telegram-бота
13 мин
О чём эта статья?
Эта статья — краткий рассказ о том, как с помощью подручных средств (Firefox) и Python можно осуществить успешную интеграцию Telegram-бота и внешнего сервиса.
Материал будет интересен тем, кто наслышан о Telegram'ных ботах, но не знает, как к ним подступиться и какие задачи с их помощью можно решать. Предполагается знание Python.
Картинка для привлечения внимания:

(ссылка на оригинал)
TL;DR
Из статьи вы узнаете:
1. Как с помощью браузера узнать, какой запрос отправляется на сервер при клике по кнопке?
Ответ
Используя web tool вашего любимого браузера можно увидеть все запросы, которые отправляются из открытой страницы на сервер.
2. Как легко отправить запрос на сервер с помощью Python?
Ответ
Удобной обёрткой над стандартным модулем
urllib2 является библиотека requests. Подробнее на Хабре: "Библиотека для упрощения HTTP-запросов".3. Как написать бота на Python?
Ответ
Полнофункциональная обёртка реализована в библиотеке
python-telegram-bot. Пока на Хабре эта библиотека не упоминалась.Байесовская нейронная сеть — потому что а почему бы и нет, черт возьми (часть 1)
16 мин
То, о чем я попытаюсь сейчас рассказать, выглядит как настоящая магия.
Если вы что-то знали о нейронных сетях до этого — забудьте это и не вспоминайте, как страшный сон.
Если вы не знали ничего — вам же легче, полпути уже пройдено.
Если вы на «ты» с байесовской статистикой, читали вот эту и вот эту статьи из Deepmind — не обращайте внимания на предыдущие две строчкии разрешите потом записаться к вам на консультацию по одному богословскому вопросу.
Итак, магия:

Слева — обычная и всем знакомая нейронная сеть, у которой каждая связь между парой нейронов задана каким-то числом (весом). Справа — нейронная сеть, веса которой представлены не числами, а демоническими облаками вероятности, колеблющимися всякий раз, когда дьявол играет в кости со вселенной. Именно ее мы в итоге и хотим получить. И если вы, как и я, озадаченно трясете головой и спрашиваете «а нафига все это нужно» — добро пожаловать под кат.
Если вы что-то знали о нейронных сетях до этого — забудьте это и не вспоминайте, как страшный сон.
Если вы не знали ничего — вам же легче, полпути уже пройдено.
Если вы на «ты» с байесовской статистикой, читали вот эту и вот эту статьи из Deepmind — не обращайте внимания на предыдущие две строчки
Итак, магия:
Слева — обычная и всем знакомая нейронная сеть, у которой каждая связь между парой нейронов задана каким-то числом (весом). Справа — нейронная сеть, веса которой представлены не числами, а демоническими облаками вероятности, колеблющимися всякий раз, когда дьявол играет в кости со вселенной. Именно ее мы в итоге и хотим получить. И если вы, как и я, озадаченно трясете головой и спрашиваете «а нафига все это нужно» — добро пожаловать под кат.
Разбираемся с войной нейронных сетей (GAN)
7 мин
Generative adversarial networks (GAN) пользуются все большей популярностью. Многие говорят о них, кто-то даже уже использует… но, как выясняется, пока мало кто (даже из тех кто пользуется) понимает и может объяснить. ;-)
Давайте разберем на самом простом примере, как же они работают, чему учатся и что на самом деле порождают.
Давайте разберем на самом простом примере, как же они работают, чему учатся и что на самом деле порождают.
Рекурентная нейронная сеть в 10 строчек кода оценила отзывы зрителей нового эпизода “Звездных войн”
11 мин
Hello, Habr! Недавно мы получили от “Известий” заказ на проведение исследования общественного мнения по поводу фильма «Звёздные войны: Пробуждение Силы», премьера которого состоялась 17 декабря. Для этого мы решили провести анализ тональности российского сегмента Twitter по нескольким релевантным хэштегам. Результата от нас ждали всего через 3 дня (и это в самом конце года!), поэтому нам нужен был очень быстрый способ. В интернете мы нашли несколько подобных онлайн-сервисов (среди которых sentiment140 и tweet_viz), но оказалось, что они не работают с русским языком и по каким-то причинам анализируют только маленький процент твитов. Нам помог бы сервис AlchemyAPI, но ограничение в 1000 запросов в сутки нас также не устраивало. Тогда мы решили сделать свой анализатор тональности с блэк-джеком и всем остальным, создав простенькую рекурентную нейронную сеть с памятью. Результаты нашего исследования были использованы в статье “Известий”, опубликованной 3 января.

В этой статье я немного расскажу о такого рода сетях и познакомлю с парой классных инструментов для домашних экспериментов, которые позволят строить нейронные сети любой сложности в несколько строк кода даже школьникам. Добро пожаловать под кат.
В этой статье я немного расскажу о такого рода сетях и познакомлю с парой классных инструментов для домашних экспериментов, которые позволят строить нейронные сети любой сложности в несколько строк кода даже школьникам. Добро пожаловать под кат.
Scalding: повод перейти с Java на Scala
8 мин

В этой статье я расскажу о Twitter Scalding – фреймворке для описания процесса обработки данных в Apache Hadoop. Я начну издалека, с истории фреймворков поверх Hadoop. Потом дам обзор возможностей Scalding. В завершение покажу примеры кода, доступные для понимания тем, кто знает Java, но почти не знаком со Scala.
Интересно? Поехали!
Кластеризация графов и поиск сообществ. Часть 1: введение, обзор инструментов и Волосяные Шары
10 мин
Привет, Хабр! В нашей работе часто возникает потребность в выделении сообществ (кластеров) разных объектов: пользователей, сайтов, продуктовых страниц интернет-магазинов. Польза от такой информации весьма многогранна – вот лишь несколько областей практического применения качественных кластеров:
 С точки зрения машинного обучения получение подобных связанных групп выглядит как типичная задача кластеризации. Однако не всегда нам бывают легко доступны фичи наблюдений, в пространстве которых можно было бы искать кластеры. Контентые или семантические фичи достаточно трудоемки в получении, как и интеграция разных источников данных, откуда эти фичи можно было бы достать. Зато у нас есть DMP под названием Facetz.DCA, где на поверхности лежат факты посещений пользователями страниц. Из них легко получить количество посещений сайтов, как каждого в отдельности, так и совместных посещений для каждой пары сайтов. Этой информации уже достаточно для построения графов веб-доменов или продуктовых страниц. Теперь задачу кластеризации можно сформулировать как задачу выделения сообществ в полученных графах.
С точки зрения машинного обучения получение подобных связанных групп выглядит как типичная задача кластеризации. Однако не всегда нам бывают легко доступны фичи наблюдений, в пространстве которых можно было бы искать кластеры. Контентые или семантические фичи достаточно трудоемки в получении, как и интеграция разных источников данных, откуда эти фичи можно было бы достать. Зато у нас есть DMP под названием Facetz.DCA, где на поверхности лежат факты посещений пользователями страниц. Из них легко получить количество посещений сайтов, как каждого в отдельности, так и совместных посещений для каждой пары сайтов. Этой информации уже достаточно для построения графов веб-доменов или продуктовых страниц. Теперь задачу кластеризации можно сформулировать как задачу выделения сообществ в полученных графах.
- Выделение сегментов пользователей для проведения таргетированных рекламных кампаний.
- Использование кластеров в качестве предикторов («фичей») в персональных рекомендациях (в content-based методах или как дополнительная информация в коллаборативной фильтрации).
- Снижение размерности в любой задаче машинного обучения, где в качестве фичей выступают страницы или домены, посещенные пользователем.
- Сличение товарных URL между различными интернет-магазинами с целью выявления среди них групп, соответствующих одному и тому же товару.
- Компактная визуализация — человеку будет проще воспринимать структуру данных.
С точки зрения машинного обучения получение подобных связанных групп выглядит как типичная задача кластеризации. Однако не всегда нам бывают легко доступны фичи наблюдений, в пространстве которых можно было бы искать кластеры. Контентые или семантические фичи достаточно трудоемки в получении, как и интеграция разных источников данных, откуда эти фичи можно было бы достать. Зато у нас есть DMP под названием Facetz.DCA, где на поверхности лежат факты посещений пользователями страниц. Из них легко получить количество посещений сайтов, как каждого в отдельности, так и совместных посещений для каждой пары сайтов. Этой информации уже достаточно для построения графов веб-доменов или продуктовых страниц. Теперь задачу кластеризации можно сформулировать как задачу выделения сообществ в полученных графах. Стипендиальные правительственные программы по всему миру. Часть 1
5 мин
Recovery Mode

Если вы собираетесь учиться да рубежом, а курс доллара и евро не вызывает положительных эмоций, то есть несколько основных источников финансирования, с которых нужно начать поиски. Расскажем подробнее об одном из них.
Все дело не в количестве строк кода. От серийного разработчика модулей
3 мин
Перевод
Синдре Сорхус — автор более, чем 600 модулей npm (666, Карл!). В недавнем AMA (кто не знает, это такой формат, когда кто-либо известный/интересный предлагает позадавать ему вопросы, например, в виде тикетов к гит-репозиторию, хотя, конечно, известнее /r/AMA и фуршет у Лебедева) он пояснил свою позицию по поводу модулей-однострочников, которые зачастую вызывают критику в адрес node.
Я собирался написать пост в блоге на эту тему, но, к сожалению, в этом я не так продуктивен, как в написании кода.
tl;dr Небольшие специализированные модули нужны для повторного использования и для того, чтобы делать большие и сложные штуки, которые легко понять.
Люди слишком озабочены количеством строк кода. LOC вообще не имеет никакого значения. Не важно, состоит модуль из одной строчки, или из сотен. Все дело в сокрытии сложности. Думайте о модулях node как о кубиках лего. Вас не интересует, из чего и как они сделаны. Все, что вам требуется знать — как использовать эти кубики для постройки своего лего-замка. Делая маленькие и специализированные модули, вы можете легко строить большие и комплексные системы без контроля за тем, как каждая отдельная деталь работает. Наша кратковременная память конечна. Эти модули могут повторно использовать другие люди и каждое улучшение и исправленный баг получат все из них.
Представьте себе, если бы производители ПК производили процессоры сами. Большинство делали бы это плохо. Компьютеры были бы дороже, а инновации происходили бы медленнее. Вместо этого большинство использует Intel, ARM и прочие.
Я собирался написать пост в блоге на эту тему, но, к сожалению, в этом я не так продуктивен, как в написании кода.
tl;dr Небольшие специализированные модули нужны для повторного использования и для того, чтобы делать большие и сложные штуки, которые легко понять.
Люди слишком озабочены количеством строк кода. LOC вообще не имеет никакого значения. Не важно, состоит модуль из одной строчки, или из сотен. Все дело в сокрытии сложности. Думайте о модулях node как о кубиках лего. Вас не интересует, из чего и как они сделаны. Все, что вам требуется знать — как использовать эти кубики для постройки своего лего-замка. Делая маленькие и специализированные модули, вы можете легко строить большие и комплексные системы без контроля за тем, как каждая отдельная деталь работает. Наша кратковременная память конечна. Эти модули могут повторно использовать другие люди и каждое улучшение и исправленный баг получат все из них.
Представьте себе, если бы производители ПК производили процессоры сами. Большинство делали бы это плохо. Компьютеры были бы дороже, а инновации происходили бы медленнее. Вместо этого большинство использует Intel, ARM и прочие.
Как нейронные сети рисуют картины
3 мин
Перевод
Умные алгоритмы уже умеют находить и распознавать лица, определять главную часть картинки, узнавать различные предметы. А нейронные сети пошли дальше и даже могут самостоятельно создавать произведения искусства.
Недавно Google на своем блоге опубликовали интересный способ использования нейронных сетей, распознающих картинки. Далее свободный перевод публикации.
Недавно Google на своем блоге опубликовали интересный способ использования нейронных сетей, распознающих картинки. Далее свободный перевод публикации.
Иерархическая классификация сайтов на Python
8 мин
Привет, Хабр! Как упоминалось в прошлой статье, немаловажной частью нашей работы является сегментация пользователей. Как же мы это делаем? Наша система видит пользователей как уникальные идентификаторы cookies, которые им присваиваем мы или наши поставщики данных. Выглядит этот id, например, так:
Эти номера выступают ключами в различных таблицах, но первоначальным value является, в первую очередь, URL страниц, на которых данная кука была загружена, поисковые запросы, а также иногда некоторая дополнительная информация, которую даёт поставщик – IP-адрес, timestamp, информация о клиенте и прочее. Эти данные довольно неоднородные, поэтому наибольшую ценность для сегментации представляет именно URL. Создавая новый сегмент, аналитик указывает некоторый список адресов, и если какая-то кука засветится на одной из этих страничек, то она попадает в соответствующий сегмент. Получается, что чуть ли не 90% рабочего времени таких аналитиков уходит на то, чтобы подобрать подходящий набор урлов – в результате кропотливой работы с поисковиками, Yandex.Wordstat и другими инструментами.
Получив таким образом более тысячи сегментов, мы поняли, что этот процесс нужно максимально автоматизировать и упростить, при этом иметь возможность мониторинга качества алгоритмов и предоставить аналитикам удобный интерфейс для работы с новым инструментом. Под катом я расскажу, как мы решаем эти задачи.
42bcfae8-2ecc-438f-9e0b-841575de7479Эти номера выступают ключами в различных таблицах, но первоначальным value является, в первую очередь, URL страниц, на которых данная кука была загружена, поисковые запросы, а также иногда некоторая дополнительная информация, которую даёт поставщик – IP-адрес, timestamp, информация о клиенте и прочее. Эти данные довольно неоднородные, поэтому наибольшую ценность для сегментации представляет именно URL. Создавая новый сегмент, аналитик указывает некоторый список адресов, и если какая-то кука засветится на одной из этих страничек, то она попадает в соответствующий сегмент. Получается, что чуть ли не 90% рабочего времени таких аналитиков уходит на то, чтобы подобрать подходящий набор урлов – в результате кропотливой работы с поисковиками, Yandex.Wordstat и другими инструментами.
Получив таким образом более тысячи сегментов, мы поняли, что этот процесс нужно максимально автоматизировать и упростить, при этом иметь возможность мониторинга качества алгоритмов и предоставить аналитикам удобный интерфейс для работы с новым инструментом. Под катом я расскажу, как мы решаем эти задачи.
Лекция Дмитрия Ветрова о математике больших данных: тензоры, нейросети, байесовский вывод
2 мин
Сегодня лекция одного из самых известных в России специалистов по машинному обучению Дмитрия Ветрова, который руководит департаментом больших данных и информационного поиска на факультете компьютерных наук, работающим во ВШЭ при поддержке Яндекса.
Как можно хранить и обрабатывать многомерные массивы в линейных по памяти структурах? Что дает обучение нейронных сетей из триллионов триллионов нейронов и как можно осуществить его без переобучения? Можно ли обрабатывать информацию «на лету», не сохраняя поступающие последовательно данные? Как оптимизировать функцию за время меньшее чем уходит на ее вычисление в одной точке? Что дает обучение по слаборазмеченным данным? И почему для решения всех перечисленных выше задач надо хорошо знать математику? И другое дальше.
Люди и их устройства стали генерировать такое количество данных, что за их ростом не успевают даже вычислительные мощности крупных компаний. И хотя без таких ресурсов работа с данными невозможна, полезными их делают люди. Сейчас мы находимся на этапе, когда информации так много, что традиционные математические методы и модели становятся неприменимы. Из лекции Дмитрия Петровича вы узнаете, почему вам надо хорошо знать математику для работы с машинным обучением и обработкой данных. И какая «новая математика» понадобится вам для этого. Слайды презентации — под катом.
Как можно хранить и обрабатывать многомерные массивы в линейных по памяти структурах? Что дает обучение нейронных сетей из триллионов триллионов нейронов и как можно осуществить его без переобучения? Можно ли обрабатывать информацию «на лету», не сохраняя поступающие последовательно данные? Как оптимизировать функцию за время меньшее чем уходит на ее вычисление в одной точке? Что дает обучение по слаборазмеченным данным? И почему для решения всех перечисленных выше задач надо хорошо знать математику? И другое дальше.
Люди и их устройства стали генерировать такое количество данных, что за их ростом не успевают даже вычислительные мощности крупных компаний. И хотя без таких ресурсов работа с данными невозможна, полезными их делают люди. Сейчас мы находимся на этапе, когда информации так много, что традиционные математические методы и модели становятся неприменимы. Из лекции Дмитрия Петровича вы узнаете, почему вам надо хорошо знать математику для работы с машинным обучением и обработкой данных. И какая «новая математика» понадобится вам для этого. Слайды презентации — под катом.
Потоковая обработка данных при помощи Akka
5 мин
Привет, Хабр! Все привыкли ассоциировать обработку больших данных с Hadoop (или Spark), которые реализуют парадигму MapReduce (или его расширения). В этой статье я расскажу о недостатках MapReduce, о том, почему мы приняли решение отказываться от MapReduce, и как мы приспособили Akka + Akka Cluster на замену MapReduce.

Как я повышал конверсию машинным обучением
8 мин
В этой статье я попробую ответить на такие вопросы:
Ответ на первый вопрос будет самым лаконичным — «да». Услышав это выступление bobuk на YaC/M, я восхитился элегантностью подхода и задумался о том, как бы внедрить похожее решение. Я тогда работал продуктовым менеджером в компании Wargaming и как раз занимался т.н. user acquisition services – технологическими решениями для привлечения пользователей, в число которых входила и система для A/B тестирования лендингов. Так что зерна легли на благодатную почву.
К сожалению, по всяким причинам я не мог плотно заняться этим проектом в обычном рабочем режиме. Зато когда я слегка перегорел на работе и решил устроить себе длинный творческий отпуск, одержимость превратилась в желание сделать такой сервис умной ротации лендингов самостоятельно.
- может ли один доклад умного человека сделать другого человека одержимым?
- как окунуться в машинное обучение (почти) с нуля?
- почему не стоит недооценивать многоруких бандитов?
- существует ли серебряная пуля для a/b тестов?
Ответ на первый вопрос будет самым лаконичным — «да». Услышав это выступление bobuk на YaC/M, я восхитился элегантностью подхода и задумался о том, как бы внедрить похожее решение. Я тогда работал продуктовым менеджером в компании Wargaming и как раз занимался т.н. user acquisition services – технологическими решениями для привлечения пользователей, в число которых входила и система для A/B тестирования лендингов. Так что зерна легли на благодатную почву.
К сожалению, по всяким причинам я не мог плотно заняться этим проектом в обычном рабочем режиме. Зато когда я слегка перегорел на работе и решил устроить себе длинный творческий отпуск, одержимость превратилась в желание сделать такой сервис умной ротации лендингов самостоятельно.
Бесплатный учебник электроники, архитектуры компьютера и низкоуровневого программирования на русском языке
2 мин
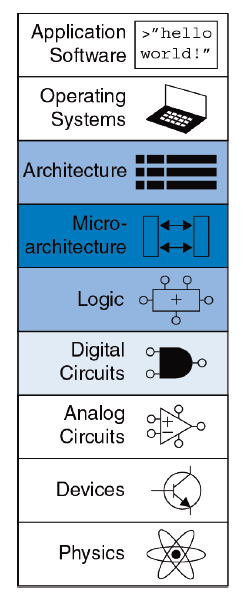
Господа! Я рад сообщить, что наконец-то все желающие могут загрузить бесплатный учебник на более чем 1600 страниц, над переводом которого работало более полусотни человек из ведущих университетов, институтов и компаний России, Украины, США и Великобритании. Это был реально народный проект и пример международной кооперации.
Учебник Дэвида Харриса и Сары Харрис «Цифровая схемотехника и архитектура компьютера», второе издание, 2012, сводит вместе миры программного обеспечения и аппаратуры, являясь одновременно введением и в разработку микросхем, и в низкоуровневое программирование для студентов младших курсов. Этот учебник превосходит более ранний вводный учебник «Архитектура компьютера и проектирование компьютерных систем» от Дэвида Паттерсона и Джона Хеннесси, причем соавтор предыдущего учебника Дэвид Паттерсон сам рекомендовал учебник от Харрисов как более продвинутый. Следуя новому учебнику, студенты строят реализацию подмножества архитектуры MIPS, используя платы с ПЛИС / FPGA, после чего сравнивают эту реализацию с индустриальными микроконтроллерами Microchip PIC32. Таким образом вводится вместе схемотехника, языки описания аппаратуры Verilog и VHDL, архитектура компьютера, микроархитектура (организация процессорного конвейера) и программирование на ассемблере — в общем все, что находится между физикой и высокоуровневым программированием.
Как загрузить? К сожалению, не одним кликом. Сначало надо зарегистрироваться в пользовательском коммьюнити Imagination Technologies, потом зарегистрироваться в образовательных программах на том же сайте, после чего наконец скачать:
Chatbot на нейронных сетях
5 мин
Недавно набрел на такую статью. Как оказалось некая компания с говорящим названием «наносемантика» объявила конкурс русских чатботов помпезно назвав это «Тестом Тьюринга»». Лично я отношусь к подобным начинаниям отрицательно — чатбот — программа для имитации разговора — создание, как правило, не умное, основанное на заготовленных шаблонах, и соревнования их науку не двигают, зато шоу и внимание публики обеспечено. Создается почва для разных спекуляций про разумные компьютеры и великие прорывы в искусственном интеллекте, что крайне далеко от истины. Особенно в данном случае, когда принимаются только боты написанные на движке сопоставления шаблонов, причем самой компании «Наносемантика».
Впрочем, ругать других всегда легко, а вот сделать что-то работающее бывает не так просто. Мне стало любопытно, можно ли сделать чатбот не ручным заполнением шаблонов ответа, а с помощью обучения нейронной сети на образцах диалогов. Быстрый поиск в Интернете полезной информации не дал, поэтому я решил быстро сделать пару экспериментов и посмотреть что получится.
Впрочем, ругать других всегда легко, а вот сделать что-то работающее бывает не так просто. Мне стало любопытно, можно ли сделать чатбот не ручным заполнением шаблонов ответа, а с помощью обучения нейронной сети на образцах диалогов. Быстрый поиск в Интернете полезной информации не дал, поэтому я решил быстро сделать пару экспериментов и посмотреть что получится.
Как попасть в топ на Kaggle, или Матрикснет в домашних условиях
9 мин
Хочу поделиться опытом участия в конкурсе Kaggle и алгоритмами машинного обучения, с помощью которых добрался до 18-го места из 1604 в конкурсе Avazu по прогнозированию CTR (click-through rate) мобильной рекламы. В процессе работы попытался воссоздать оригинальный алгоритм Мактрикснета, тестировал несколько вариантов логистической регрессии и работал с характеристиками. Обо всём этом ниже, плюс прикладываю полный код, чтобы можно было посмотреть, как всё работает.
Рассказ делю на следующие разделы:
1. Условия конкурса;
2. Создание новых характеристик;
3. Логистическая регрессия – прелести адаптивного градиента;
4. Матрикснет – воссоздание полного алгоритма;
5. Ускорение машинного обучения в Python.
Рассказ делю на следующие разделы:
1. Условия конкурса;
2. Создание новых характеристик;
3. Логистическая регрессия – прелести адаптивного градиента;
4. Матрикснет – воссоздание полного алгоритма;
5. Ускорение машинного обучения в Python.