Содержимое: как сделать так, чтобы компьютер отвечал в интернете на все свои IP-адреса по всем своим интерфейсам, каждый из которых имеет шлюз по умолчанию. Касается и серверов, и десктопов.
Ключевые слова: policy routing, source based routing
Лирика: Есть достаточно статей про policy routing в Linux. Но они чаще всего разбирают общие, более тонкие и сложные случаи. Я же разберу тривиальный сценарий следующего вида:
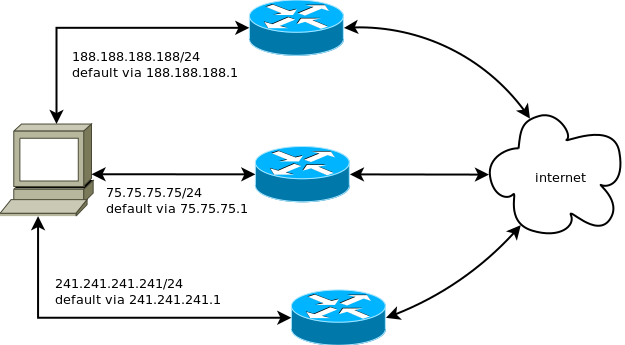
Нашему компьютеру (серверу) доступно три интерфейса. На каждом интерфейсе шлюз ему выдал IP (статикой или по dhcp, не важно) и сказал «весь трафик шли мне».
Если мы оставим эту конфигурацию как есть, то будет использоваться принцип «кто последний встал, того и дефолтный шлюз». На картинке выше, если последним поднимется нижний интерфейс (241), то в него будет отправляться весь трафик. Если к нашему серверу придёт запрос на первый интерфейс (188), то ответ на него всё равно пойдёт по нижнему. Если у маршрутизатора/провайдера есть хотя бы минимальная защита от подделки адресов, то ответ просто дропнут, как невалидный (с точки зрения 241.241.241.1 ему прислали из сети 241.241.241.0/24 пакет с src 188.188.188.188, чего, очевидно, быть не должно).
Другими словами, в обычном варианте будет работать только один интерфейс. Чтобы сделать ситуацию хуже, если адреса получены по dhcp, то обновление аренды на других интерфейсах может перезаписать шлюз по умолчанию, что означает, что тот интерфейс, который работал, работать перестанет, а начнёт работать другой интерфейс. Удачной стабильной работы вашему серверу, так сказать.
Решение