Добрый день.
Недавно одни из наших заказчиков выразили желание получать дополнительную информацию о посетителях своего сайта, конкретнее — о людях, заполнивших контактную форму. Это крупная европейская компания и им хотелось бы «фильтровать» своих потенциальных клиентов. Поясню на примере — допустим, решают они организовать выставку своего оборудования в Венгрии и им нужно решить, кто из венгров, оставлявших им свои контакты, скорее всего стоящий клиент, а кто «мимо проходил».
Основными показателями «надежности» клиента для нас стали: число посещений сайта, время проведенное на сайте, количество просмотренных страниц. Всю эту информацию мы получили из Google Analytics Cookies.
Что же из себя представляют печеньки от Google?









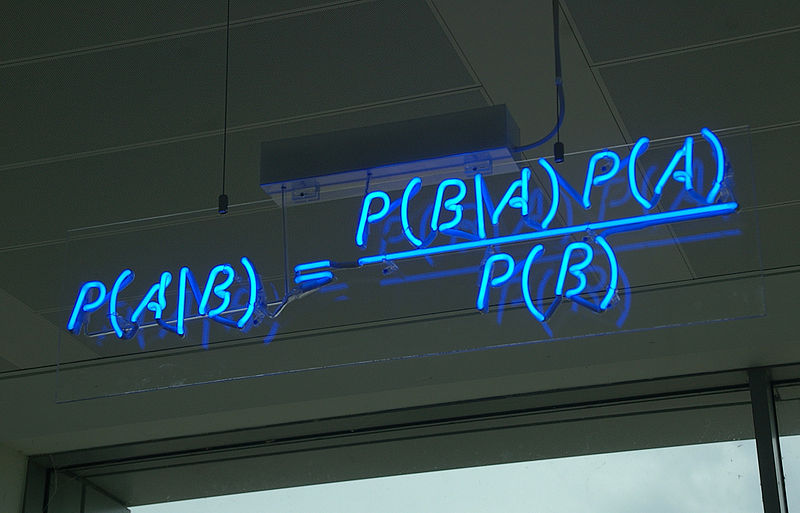
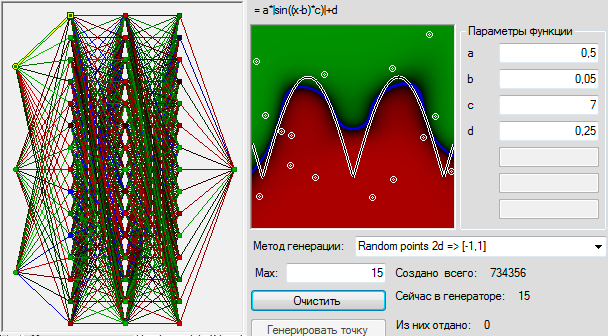 В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта:
В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта: