

Мы сделали сервис для генерации рефератов и научных статей, которые не детектируются антиплагиатом.
Потому что заметили, что за это платят. И потому что могли.
Похожие сервисы используют всеми любимые сеошники, а поисковые машины с этим борются. И такая потребность есть у студентов, которым надо быстро сдать реферат. В Болонской системе до 80 % домашних заданий могут быть в форме эссе. И это не только гуманитарная фишка, даже какому-нибудь инженеру могут дать задание написать о, например, состоянии солнечной энергетики в Техасе.
Потом преподаватель прогоняет реферат через один из инструментов антиплагиата и говорит: «Смотри, это даёт оценку 95 % AI generated. У тебя оценка ноль. Если у тебя будет вторая оценка ноль, то мы тебя отчислим».
А мы научились правильно вносить шум в тексты, чтобы они не детектировались таким образом. Потому что поняли, что генерация эссе — это потенциально огромный рынок, с LLM эта история не зависит от языка, студенты платят со всего мира.
С одной стороны, были некоторые сомнения, с другой — большинство наших пользователей используют генерацию как отправную точку для дальнейшей работы над текстом. Ну и миллион долларов в месяц тоже, конечно же, повлиял. В общем, Маша, это, конечно, Маша, но миллион — это миллион.



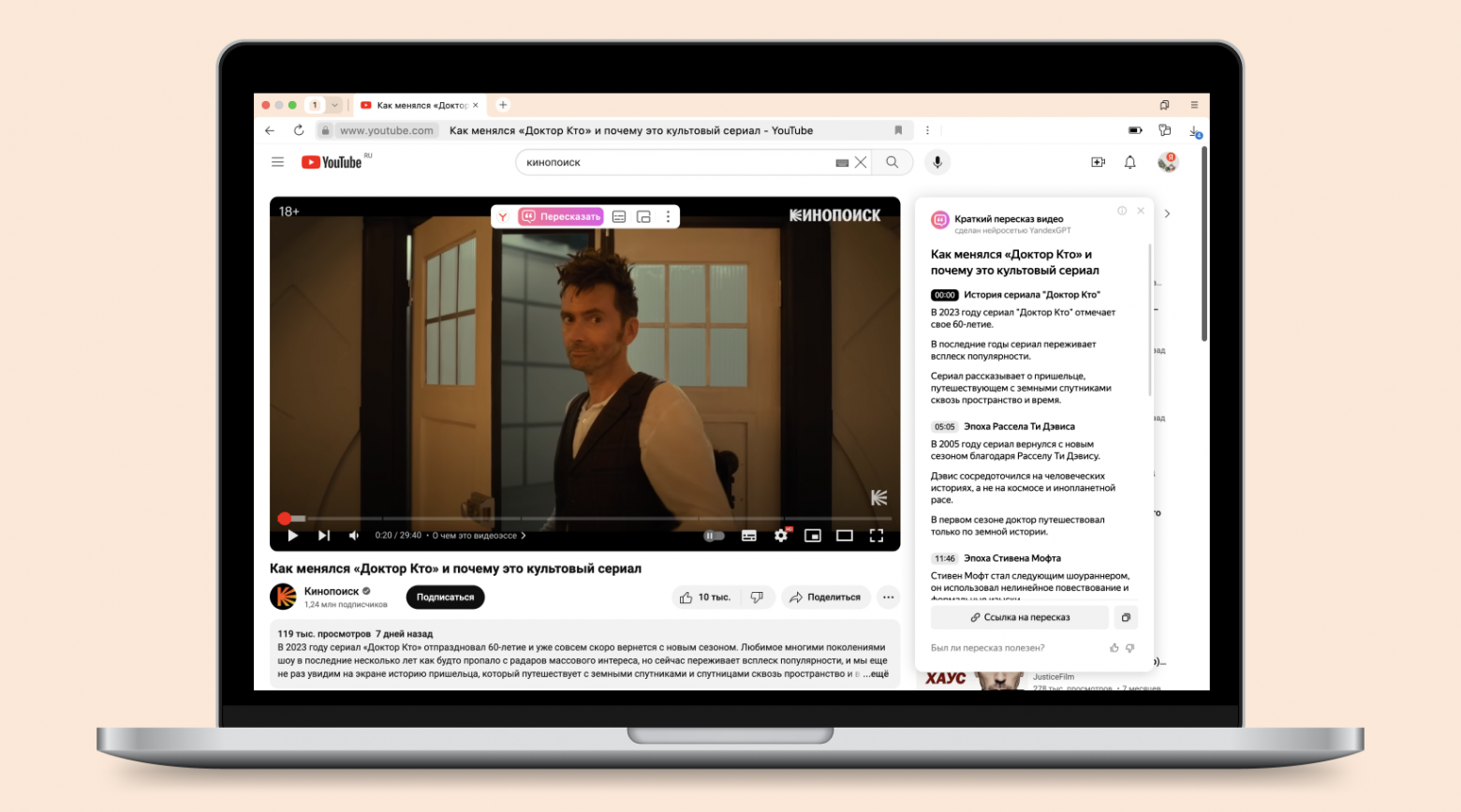
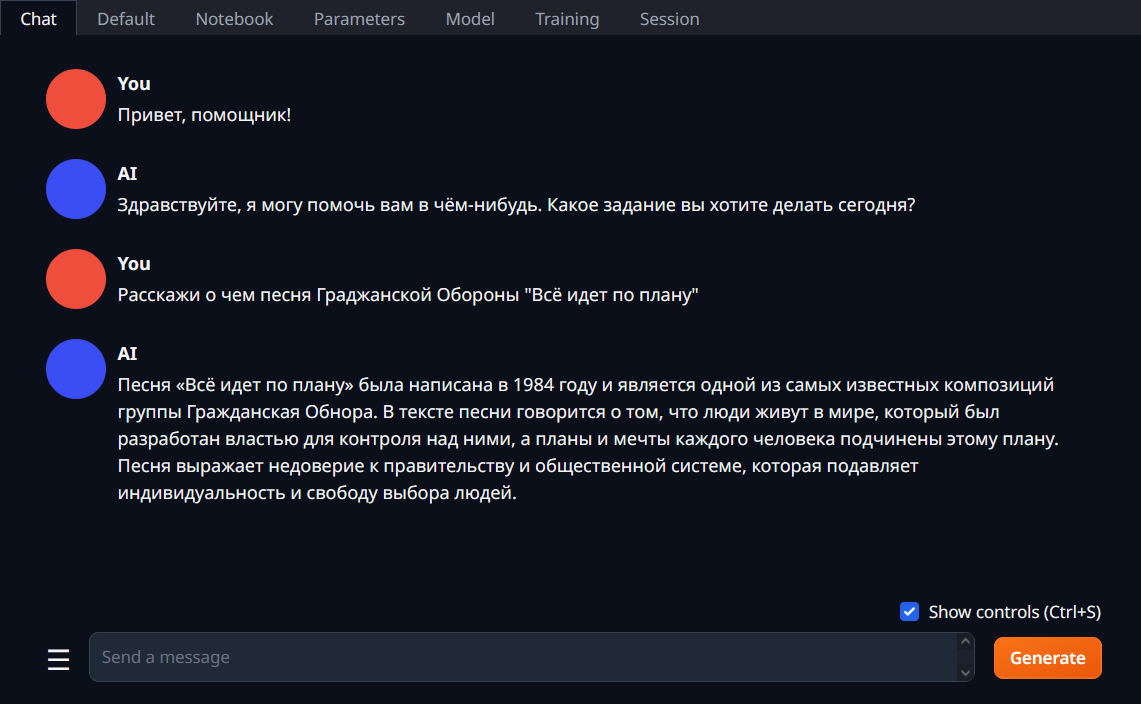




 7 сентября 2021 года мне пришло электронное письмо:
7 сентября 2021 года мне пришло электронное письмо: