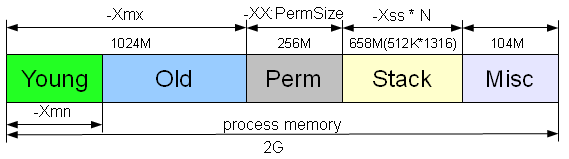
По долгу службы мне периодически приходится пользоваться профайлером, так как требования к производительности серверов задокументированы и не могут опускаться ниже определенного уровня. Помимо некоторых очевидных архитектурных изменений и решений частенько находятся повторяющиеся места от модуля к модулю, от одного проекта к другому, которые создают дополнительную нагрузку на виртуальную машину, которыми и хочу поделиться.
Так уж случилось, что на глаза чаще всего попадался код работы с Date потому с него и начнем:
Date
Не один десяток раз я имел возможность наблюдать, как во время обработки одного запроса от пользователя в нескольких разных местах создается новый объект даты. Чаще всего цель одна и та же — получить текущее время. В простейшем случае это выглядит так:
public boolean isValid(Date start, Date end) {
Date now = new Date();
return start.before(now) && end.after(now);
}
Казалось бы — вполне очевидное и правильное решение. В принципе, да, за исключением двух моментов:
- Использовать Date сегодня в java — уже, пожалуй, моветон, учитывая тот факт, что почти все методы в нем уже Deprecated.
- Нету смысла создавать новый объект даты, если вполне можно обойтись примитивом long:
public boolean isValid(Date start, Date end) {
long now = System.currentTimeMillis();
return start.getTime() < now && now < end.getTIme();
}
SimpleDateFormat
Очень часто в веб проектах возникает задача перевести строку в дату или наоборот дату в строку. Задача довольно типичная и чаще всего выглядит так:
return new SimpleDateFormat("EEE, d MMM yyyy HH:mm:ss Z").parse(dateString);
Это правильное и быстрое решение, но если серверу приходится парсить строку на каждый пользовательский реквест в каждом из сотен потоков — это может ощутимо бить по производительности сервера в виду довольно тяжеловесного конструктора SimpleDateFormat, да и помимо самого форматера создается множество других объектов в том числе и не легкий Calendar (размер которого > 400 байт).
Ситуацию можно было бы легко решить, сделав SimpleDateFormat статическим полем, но он не является потокобезопасным. И в конкурентной среде легко можно словить NumberFormatException.
Вторая мысль — использовать синхронизацию. Но это таки довольно сомнительная вещь. В случае большой конкуренции между потоками, мы можем не просто не улучшить производительность но и ухудшить.
Но решения есть и их как минимум 2:
- Старый, добрый ThreadLocal — cоздаем SimpleDateFormat для каждого потока 1 раз и переиспользуем для каждого последующего запроса. Данный подход поможет ускорить парсинг даты в 2-4 раза за счет избежания создания объектов SimpleDateFormat на каждый запрос.
- Joda и ее потокобезопасный аналог SimpleDateFormat — DateTimeFormat. Хоть йода в целом и медленнее дефолтного Java Date API в парсинге дат они идут наравне. Несколько тестов можно глянуть тут.




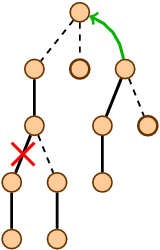 Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы. 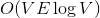 и
и 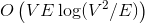 соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.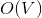 памяти и
памяти и 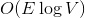 времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.