
Манга «Занимательная статистика», «Тайна катастроф» и другие похожие книги
5 мин
Речь идет о необычных учебниках, которые стоят посередине между вузовскими учебниками и чисто научно-популярными брошюрами. Тем не менее между научпопом и такими учебниками есть четкий водораздел — последние нацелены именно на обучение, развлекательные фишки — лишь форма подачи серьезного материала. Общее для всех таких книг, как мне представляется — подача материала в виде комикса и\или в виде диалога двух или больше людей. Обычно два собеседника — ученик и учитель, один постоянно задает вопросы, часто глупые или смешные, второй пытается объяснить в игровой форме.
В посте много скриншотов нескольких книг. Одну из них, которая про катастрофы я полностью переснял и выложил pdf. Прошу учесть, под хабракатом не один мегабайт картинок, текста много меньше. Заранее прошу прощения за качество некоторых кадров — ночная пересъемка не способствовала. Возможно, картинок больше, чем нужно, но я старался и показать основные принципы — графический, игровой способ подачи материала, сюжет и диалоги.
Я сделал что-то вроде ретроспективы: первая книга — свежий японский комикс-манга о матстатистики издания 2010 года, дальше — книга из 80-х о математике, теории катасроф. Последняя — учебник радиоэлектроники для начинающих, знакомый нескольким поколениям читателей по всему миру, начиная с 30-х годов.
В качестве иллюстрации поста приведу обложку другой манги из той же серии, что и книга о статистике:

В посте много скриншотов нескольких книг. Одну из них, которая про катастрофы я полностью переснял и выложил pdf. Прошу учесть, под хабракатом не один мегабайт картинок, текста много меньше. Заранее прошу прощения за качество некоторых кадров — ночная пересъемка не способствовала. Возможно, картинок больше, чем нужно, но я старался и показать основные принципы — графический, игровой способ подачи материала, сюжет и диалоги.
Я сделал что-то вроде ретроспективы: первая книга — свежий японский комикс-манга о матстатистики издания 2010 года, дальше — книга из 80-х о математике, теории катасроф. Последняя — учебник радиоэлектроники для начинающих, знакомый нескольким поколениям читателей по всему миру, начиная с 30-х годов.
В качестве иллюстрации поста приведу обложку другой манги из той же серии, что и книга о статистике:
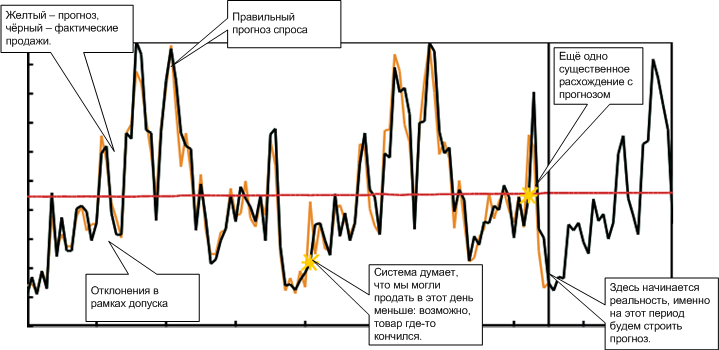

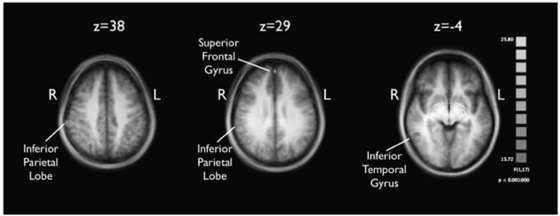










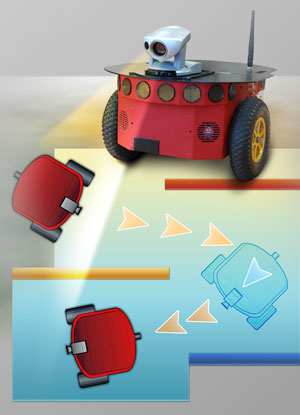
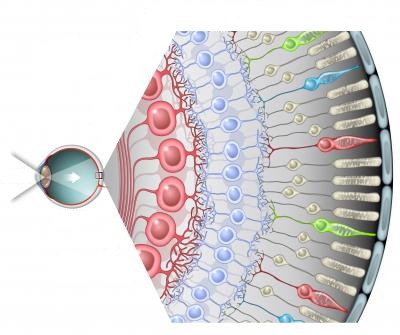 Привет. В этом посте мы проведем эксперимент, в котором протестируем два типа
Привет. В этом посте мы проведем эксперимент, в котором протестируем два типа 

{kind=link}