Этот восхитительный Юникод
27 мин
Перевод

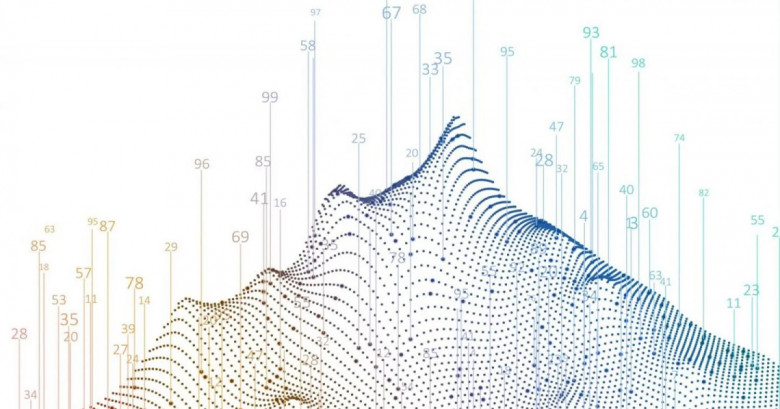
Перед вами обновляемый список самых замечательных «вкусностей» Юникода, а также пакетов и ресурсов
Юникод — это потрясающе! До его появления международная коммуникация была изнурительной: каждый определял свой отдельный расширенный набор символов в верхней половине ASCII (так называемые кодовые страницы). Это порождало конфликты. Просто подумайте, что немцам приходилось договариваться с корейцами, где чья кодовая страница. К счастью, появился Юникод и ввёл общий стандарт. Юникод 8.0 охватывает более 120 000 символов из более 129 письменностей. И современные, и древние, и до сих пор не расшифрованные. Юникод поддерживает текст слева направо и справа налево, наложение символов и включает самые разные культурные, политические, религиозные символы и эмодзи. Юникод потрясающе человечен, а его возможности сильно недооцениваются.
") ,
, )") — пересечение полуплоскостей,
— пересечение полуплоскостей, )") — алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
— алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).