От переводчика. Автор этой публикации — Роберт Мэй (Robert May), основатель компании Backupify, которая позволяет осуществлять резервирование, архивацию и экспорт информации, находящейся в различных онлайн хранилищах.
Как и многие из вас, я немало лет читал блоги про стартапы и венчуры. Я перечитал уйму постов о том, что надо писать в своих бизнес-планах и как делать финансовые прогнозы. Но в итоге это неизменно меня утомляло. Я всегда был человеком действия, а не планирования; я проявлял изобретательность, а не искал деньги. При мысли о трате бесценного рабочего времени на корпение над бизнес-планом меня изрядно мутило.
За несколько месяцев, пока я завершал привлекать инвестиции в Backupify, моё представление сильно изменилось. С одной стороны, я смог собрать деньги без бизнес-плана и финансовых прогнозов. Это радовало. С другой стороны, я узнал некоторые вещи, которые изменили моё представление о процессе поиска средств. Когда я снова буду заниматься этим для нашего следующего этапа и для будущих стартапов, я буду подходить к этому иначе, чем в этот раз. Вот я и подумал, что пока эти мысли свежи, хорошо бы записать свой опыт прохождения пути от новичка в области венчурного капитала до генерального директора компании, за которой стоят венчурные инвесторы. По прошествии времени я уже не вспомню события так подробно, а посему вот пост о том, что я узнал и чем хочу поделиться с теми из вас, кто впервые ступает на этот путь.
Как и многие из вас, я немало лет читал блоги про стартапы и венчуры. Я перечитал уйму постов о том, что надо писать в своих бизнес-планах и как делать финансовые прогнозы. Но в итоге это неизменно меня утомляло. Я всегда был человеком действия, а не планирования; я проявлял изобретательность, а не искал деньги. При мысли о трате бесценного рабочего времени на корпение над бизнес-планом меня изрядно мутило.
За несколько месяцев, пока я завершал привлекать инвестиции в Backupify, моё представление сильно изменилось. С одной стороны, я смог собрать деньги без бизнес-плана и финансовых прогнозов. Это радовало. С другой стороны, я узнал некоторые вещи, которые изменили моё представление о процессе поиска средств. Когда я снова буду заниматься этим для нашего следующего этапа и для будущих стартапов, я буду подходить к этому иначе, чем в этот раз. Вот я и подумал, что пока эти мысли свежи, хорошо бы записать свой опыт прохождения пути от новичка в области венчурного капитала до генерального директора компании, за которой стоят венчурные инвесторы. По прошествии времени я уже не вспомню события так подробно, а посему вот пост о том, что я узнал и чем хочу поделиться с теми из вас, кто впервые ступает на этот путь.

 Салют, Хабр!
Салют, Хабр!

 Мифы – это попытки осмысления картины окружающего мира, присущие первобытной культуре.
Мифы – это попытки осмысления картины окружающего мира, присущие первобытной культуре. 


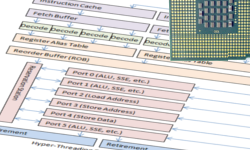 Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.