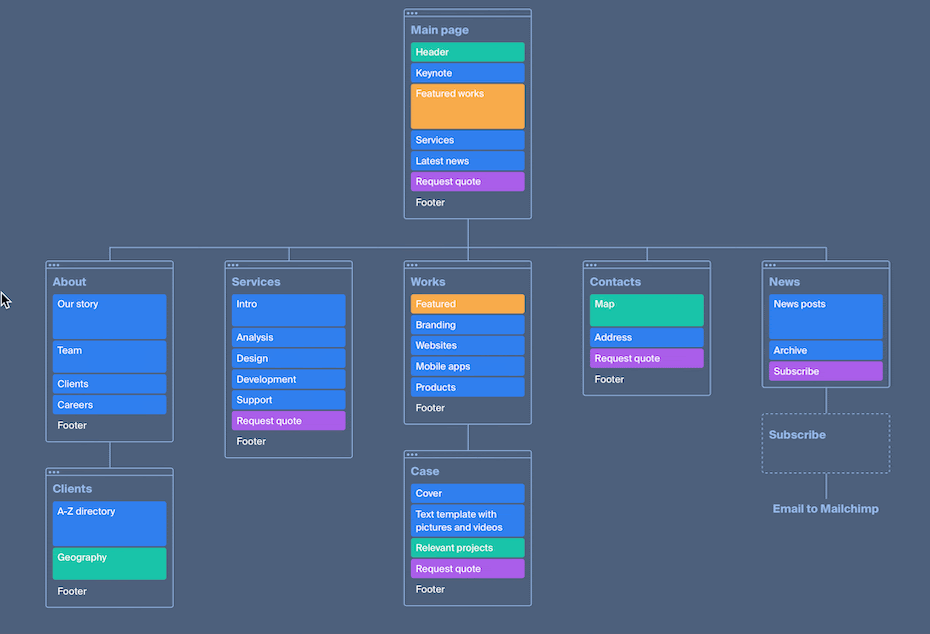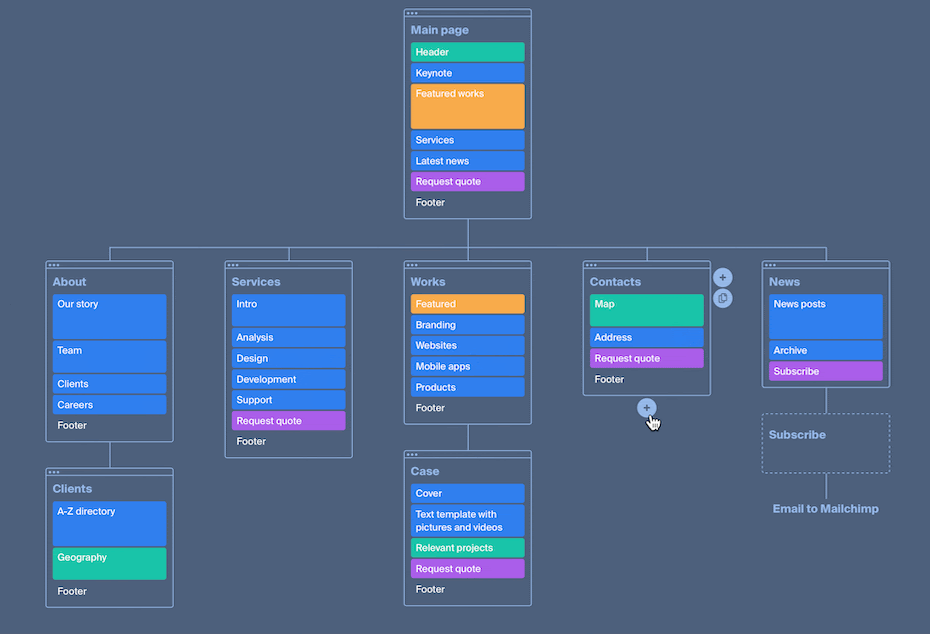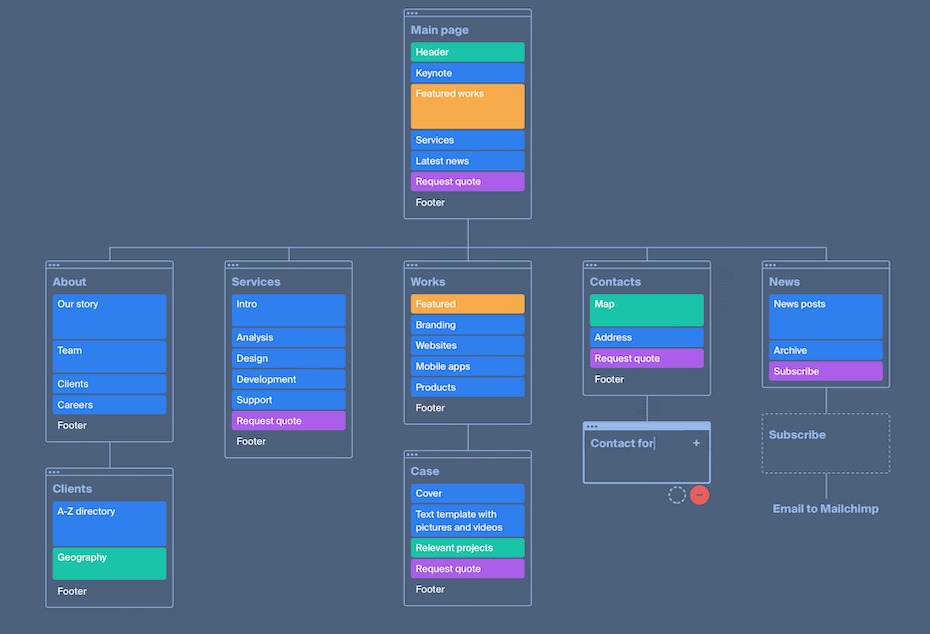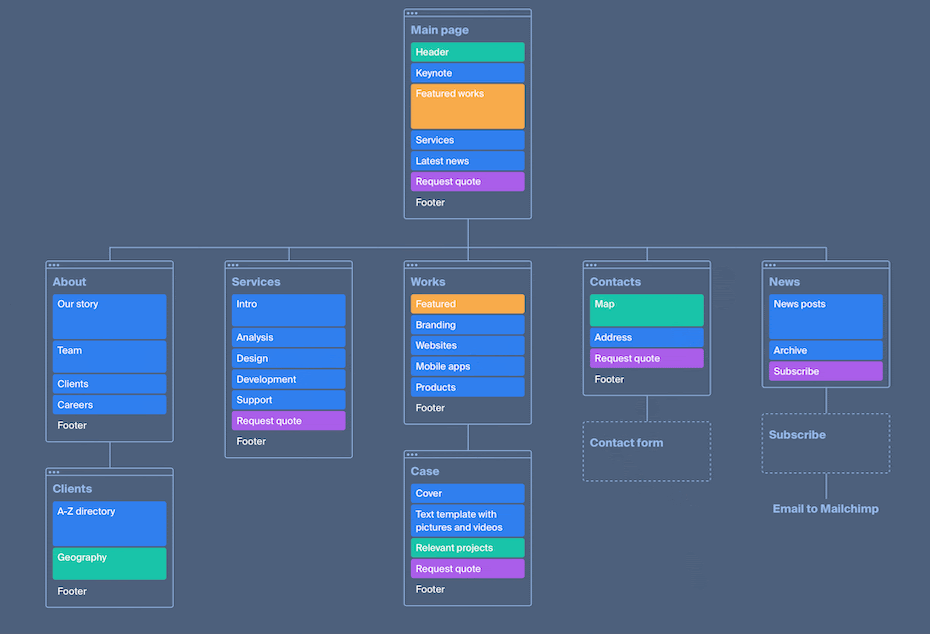
В предыдущих сериях ( 1 • 2 • 3 • 4 • 5 • 6 • 7 • Ы ) рассмотрели, как написать на Java собственный интерпретатор объектно-ориентированного диалекта SQL, заточенный на задачи подготовки и трансформации наборов данных, и работающий как тонкая прослойка поверх Spark RDD API.
Штука получилась довольно продвинутая, с поддержкой императивщины типа циклов/ветвлений/переменных, и даже с поддержкой пользовательских процедур. И в плане этой самой императивщины расширяемая: может импортировать функции из Java classpath, равно как и операторы выражений. То есть, если необходимо, можно написать функцию на Java, или определить новый оператор, и использовать потом в любом выражении на SQL.
Круто? Ещё как круто. Но как-то однобоко. Если в языке у нас поддерживаются функции, то почему бы не дать нашим пользователям определять их самостоятельно? Вот прямо через CREATE FUNCTION? Тем более, что вся необходимая для этого инфраструктура уже вовсю присутствует. Да и процедуры на уровне интерпретатора у нас уже поддерживаются ведь…

Функция для затравки.