
Что покупать для глубокого обучения: личный опыт и советы использования GPU
30 мин
Перевод
Перевод статьи Тима Деттмерса, кандидата наук из Вашингтонского университета, специалиста по глубокому обучению и обработке естественного языка
Глубокое обучение (ГО) – область с повышенными запросами к вычислительным мощностям, поэтому ваш выбор GPU фундаментально определит ваш опыт в этой области. Но какие свойства важно учесть, если вы покупаете новый GPU? Память, ядра, тензорные ядра? Как сделать лучший выбор по соотношению цены и качества? В данной статье я подробно разберу все эти вопросы, распространённые заблуждения, дам вам интуитивное представление о GPU а также несколько советов, которые помогут вам сделать правильный выбор.
Статья написана так, чтобы дать вам несколько разных уровней понимания GPU, в т.ч. новой серии Ampere от NVIDIA. У вас есть выбор:
Каждая секция предваряется небольшим резюме, которое поможет вам решить, читать её целиком или нет.
Глубокое обучение (ГО) – область с повышенными запросами к вычислительным мощностям, поэтому ваш выбор GPU фундаментально определит ваш опыт в этой области. Но какие свойства важно учесть, если вы покупаете новый GPU? Память, ядра, тензорные ядра? Как сделать лучший выбор по соотношению цены и качества? В данной статье я подробно разберу все эти вопросы, распространённые заблуждения, дам вам интуитивное представление о GPU а также несколько советов, которые помогут вам сделать правильный выбор.
Статья написана так, чтобы дать вам несколько разных уровней понимания GPU, в т.ч. новой серии Ampere от NVIDIA. У вас есть выбор:
- Если вам не интересны детали работы GPU, что именно делает GPU быстрым, чего уникального есть в новых GPU серии NVIDIA RTX 30 Ampere – можете пропустить начало статьи, вплоть до графиков по быстродействию и быстродействию на $1 стоимости, а также раздела рекомендаций. Это ядро данной статьи и наиболее ценное содержимое.
- Если вас интересуют конкретные вопросы, то наиболее частые из них я осветил в последней части статьи.
- Если вам нужно глубокое понимание того, как работают GPU и тензорные ядра, лучше всего будет прочесть статью от начала и до конца. В зависимости от ваших знаний по конкретным предметам вы можете пропустить главу-другую.
Каждая секция предваряется небольшим резюме, которое поможет вам решить, читать её целиком или нет.





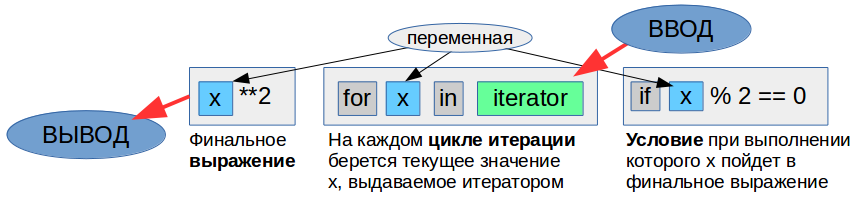
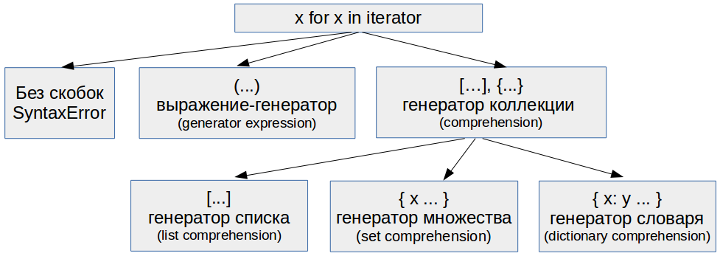
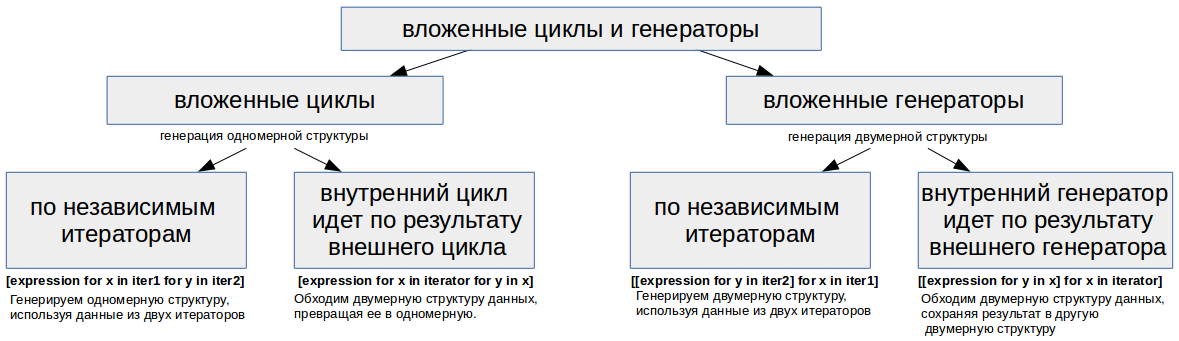
 Коллекция в Python — программный объект (переменная-контейнер), хранящая набор значений одного или различных типов, позволяющий обращаться к этим значениям, а также применять специальные функции и методы, зависящие от типа коллекции.
Коллекция в Python — программный объект (переменная-контейнер), хранящая набор значений одного или различных типов, позволяющий обращаться к этим значениям, а также применять специальные функции и методы, зависящие от типа коллекции.  Здравствуйте, коллеги! Это блог открытой русскоговорящей
Здравствуйте, коллеги! Это блог открытой русскоговорящей 


