Сегодня Redux — это одно из наиболее интересных явлений мира JavaScript. Он выделяется из сотни библиотек и фреймворков тем, что грамотно решает множество разных вопросов путем введения простой и предсказуемой модели состояний, уклоне на функциональное программирование и неизменяемые данные, предоставления компактного API. Что ещё нужно для счастья? Redux — библиотека очень маленькая, и выучить её API не сложно. Но у многих людей происходит своеобразный разрыв шаблона — небольшое количество компонентов и добровольные ограничения чистых функций и неизменяемых данных могут показаться неоправданным принуждением. Каким именно образом работать в таких условиях?
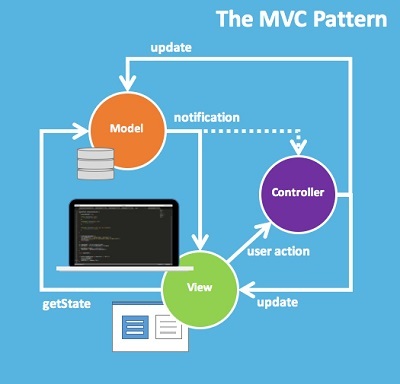
Сегодня Redux — это одно из наиболее интересных явлений мира JavaScript. Он выделяется из сотни библиотек и фреймворков тем, что грамотно решает множество разных вопросов путем введения простой и предсказуемой модели состояний, уклоне на функциональное программирование и неизменяемые данные, предоставления компактного API. Что ещё нужно для счастья? Redux — библиотека очень маленькая, и выучить её API не сложно. Но у многих людей происходит своеобразный разрыв шаблона — небольшое количество компонентов и добровольные ограничения чистых функций и неизменяемых данных могут показаться неоправданным принуждением. Каким именно образом работать в таких условиях?В этом руководстве мы рассмотрим создание с нуля full-stack приложения с использованием Redux и Immutable-js. Применив подход TDD, пройдём все этапы конструирования Node+Redux бэкенда и React+Redux фронтенда приложения. Помимо этого мы будем использовать такие инструменты, как ES6, Babel, Socket.io, Webpack и Mocha. Набор весьма любопытный, и вы мигом его освоите!

 В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.
В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.