
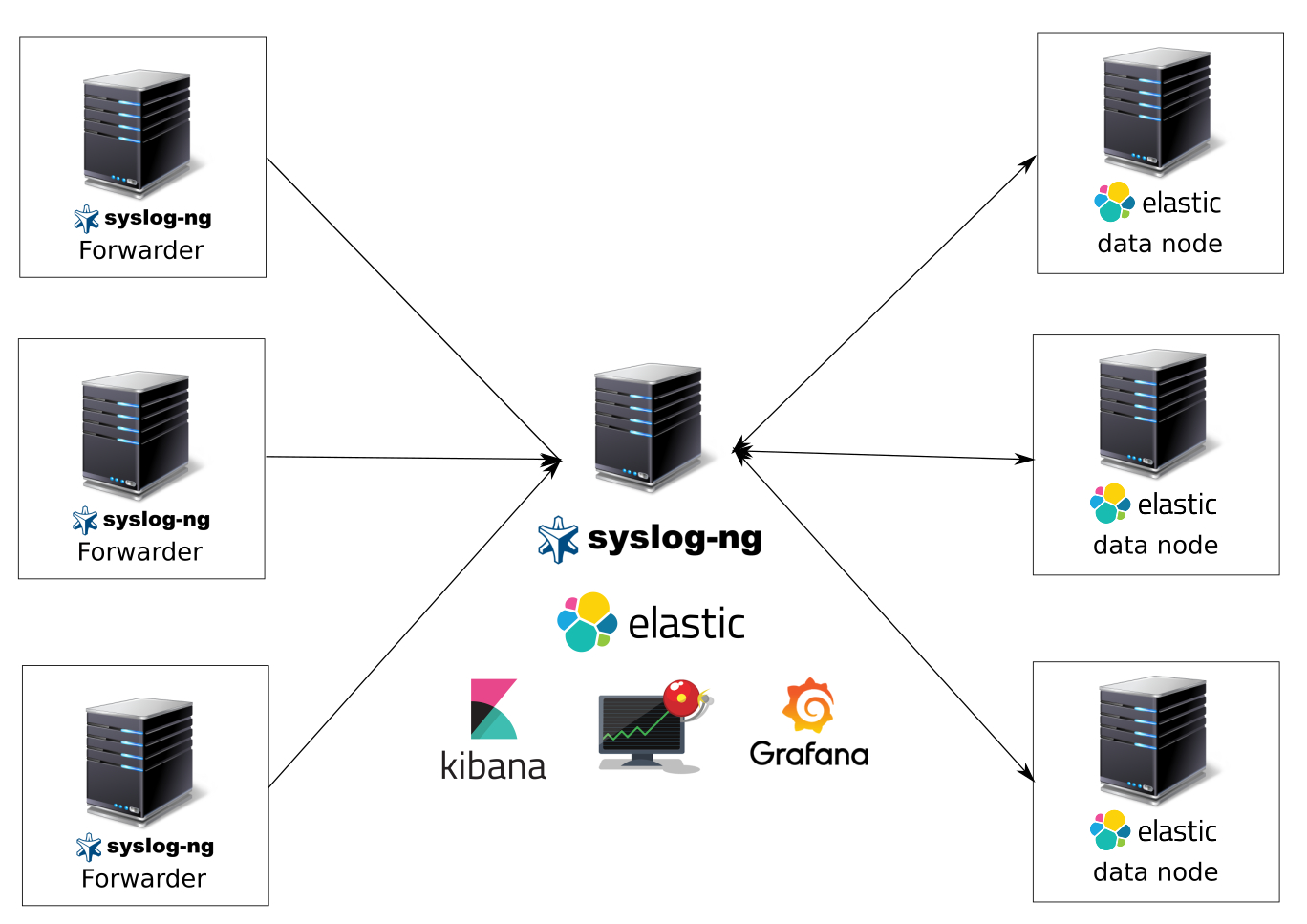
Что мы получим после этой статьи:
Систему сбора и анализа логов на syslog-ng, elasticsearch в качестве хранилища данных, kibana и grafana в качестве систем визуализации данных, kibana для удобного поиска по логам, elasticalert для отправки уведомлений по событиям. Приготовьтесь, туториал объемный.
Какие логи будем собирать:
- все системные логи разложенные по индексам в зависимости от их facility(auth,syslog,messages и т.д.);
- логи nginx — access и error;
- логи pm2;
- и др.
Обоснование выбора системы
Почему я выбрал связку с syslog-ng в качестве отправителя, парсера и приемщика логов? Да потому что он очень быстрый, надежный, не требовательный к ресурсам(да да — logstash в качестве агентов на серверах и виртуальных машинах просто убожество в плане пожирания ресурсов и требованием java), с внятным синтаксисом конфигов(вы видели rsyslog? — это тихий ужас), с широкими возможностями — парсинг, фильтрация, большое количество хранилищ данных(postgresql,mysql,elasticsearch,files и т.д.), буферизация(upd не поддерживает буферизацию), сторонние модули и другие фишки.
Требования:
- Ubuntu 16.04 или debian 8-9;
- vm для развертывания;
- Прямые руки.
Приступим или добро пожаловать под кат





 Liquibase — это система управления миграциями базы данных. Это вторая статья о Liquibase, на этот раз содержащая советы «боевого» использования системы. Для получения базовых сведений подойдет первая статья-перевод «Управление миграциями БД с Liquibase» (
Liquibase — это система управления миграциями базы данных. Это вторая статья о Liquibase, на этот раз содержащая советы «боевого» использования системы. Для получения базовых сведений подойдет первая статья-перевод «Управление миграциями БД с Liquibase» ( Рискну предположить, что среднестатистический читатель этой статьи с продуктом
Рискну предположить, что среднестатистический читатель этой статьи с продуктом 

 Большинство литературы посвященной паттернам в ООП (объектно-ориентированном программировании), как правило, объясняются на примерах с самим кодом. И это правильный подход, так как паттерны ООП уже по-умолчанию предназначаются для людей, которые знают что такое программирование и суть ООП. Однако порой требуется заинтересовать этой темой людей, которые в этом совершенно ничего не понимают, например «не-программистов» или же просто начинающих «компьютерщиков». Именно с этой целью и был подготовлен данный материал, который призван объяснить человеку любого уровня знаний, что такое паттерн ООП и, возможно, привлечет в ряды программистов новых «адептов», ведь программирование это на самом деле очень интересно.
Большинство литературы посвященной паттернам в ООП (объектно-ориентированном программировании), как правило, объясняются на примерах с самим кодом. И это правильный подход, так как паттерны ООП уже по-умолчанию предназначаются для людей, которые знают что такое программирование и суть ООП. Однако порой требуется заинтересовать этой темой людей, которые в этом совершенно ничего не понимают, например «не-программистов» или же просто начинающих «компьютерщиков». Именно с этой целью и был подготовлен данный материал, который призван объяснить человеку любого уровня знаний, что такое паттерн ООП и, возможно, привлечет в ряды программистов новых «адептов», ведь программирование это на самом деле очень интересно.