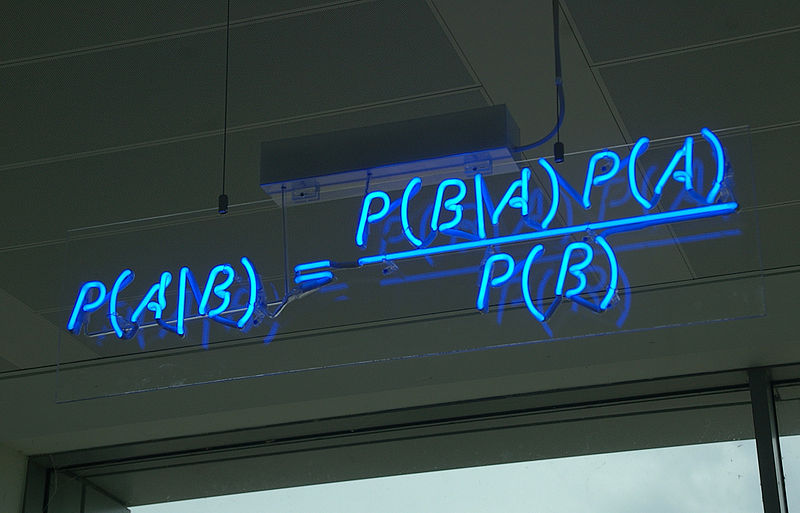Этот пост хотелось бы написать скорее в философском ключе, нежели в математическом (точнее алгебраическом): не что это за страшный зверь —
ЛСА, а какая от него может быть польза «нашему колхозу», т.е.
ИИ.
Ни для кого уже не секрет, что ИИ состоит из многих взаимонепересекающихся или слабо пересекающихся областей: распознавание образов, распознавание речи, реализации моторных функций в пространстве и пр. Но одной из главных целей ИИ – научить «железо» думать, что включает в себя не только процессы понимания, но и генерирование новой информации: свободного или творческого мышления. В связи с этим возникают вопросы не столько разработки методов обучения систем, сколько осмысления процессов мышления, возможности их реализации.
На основах работы ЛСА, как уже упоминалось в начале статьи, я не буду сейчас останавливаться (планирую в следующем посте), а пока отошлю к
Википедии, лучше даже английской (
LSA). А вот основную идею этого метода постараюсь изложить на словах.
Формально:
ЛСА используется для выявления латентных (скрытых) ассоциативно-семантических связей между термами (словами, н-граммами) путем сокращения факторного пространства термы-на-документы. Термами могут выступать как слова, так и их комбинации, т.наз. н-граммы, документами – в идеале: наборы тематически однородных текстов, либо просто любой желательно объемный текст (несколько млн. словоформ), произвольно разбитый на куски, например абзацы.
«На пальцах»:
Основная идея латентно-семантического анализа состоит в следующем: если в исходном вероятностном пространстве, состоящим из векторов слов (вектор = предложение, абзац, документ и т.п.), между двумя любыми словами из двух разных векторов может не наблюдаться никакой зависимости, то после некоторого алгебраического преобразования данного векторного пространства эта зависимость может появиться, причем величина этой зависимости будет определять силу ассоциативно-семантической связи между этими двумя словами.
Например, рассмотрим два простых сообщения из разных источников (просто пример для наглядности):

 Farbrausch, без сомнения, одна из самых популярных групп на демосцене. Они релизят технически безупречные и визуально сексуальные демы и возглавляют вершину чарта лучших групп, а
Farbrausch, без сомнения, одна из самых популярных групп на демосцене. Они релизят технически безупречные и визуально сексуальные демы и возглавляют вершину чарта лучших групп, а