Аннотация
В среднем, очередной пост про NAS появляется примерно раз в полгода, и рассказывает о том, как поставить систему по документации. Мы усложним задачу, привязав ее к реальному проекту и ограничив бюджет. Кроме того, мы еще и попытаемся подстелить себе соломку в тех местах, куда не еще не ступала нога молодого сисадмина, а также разрушим несколько отраслевых мифов.
Эта статья не для специалистов по серверному хранению данных, геймеров и прочих оверклокеров. На вас, коллеги, и так вся индустрия работает. Она для начинающих сисадминов, любителей UNIX-систем и энтузиастов свободного программного обеспечения. У всех накопилось старое железо. Всем нужно хранить большие объемы дома или в офисе. Но далеко не у всех есть простой доступ к серверным технологиям.
Я очень надеюсь, что вы найдете для себя несколько полезных идей и все-таки научитесь на чужих ошибках. Помните: система стоит не столько, сколько вы заплатили за железо, а сколько вы вложите потом времени и сил в тестирование и эксплуатацию.
Если не хотите читать — посмотрите ссылки и выводы в конце; может, и передумаете.
DISCLAIMER
Информация предоставляется AS-IS без какой-либо ответственности за ее использование кем-либо, где-либо и когда-либо. Все ненароком упомянутые торговые марки являются собственностью соответствующих владельцев. Некоторые из них в рекламе уже настолько не нуждаются, что я придумываю им шуточные названия.
Благодарности
Респект Андрею Александровичу Бахметьеву, инженеру и изобретателю. Я горд, что Андрей Александрович преподавал для меня в институте! Желаю ему всяческих успехов в его проектах!
Задача
Итак, есть малый бизнес-стартап, генерирующий порядка 50Гб файлов в неделю, с необходимостью их архивного хранения в течение нескольких лет. Файлы крупные (порядка 10-20 Мб каждый), обычными алгоритмами не сжимаемые. Начальный объем данных порядка 2Тб. Совсем старые данные можно хранить в оффлайне, подключая по требованию.
Нужно уложиться в весьма скромный
начальный бюджет решения 500 евро (в ценах лета 2013) и
двухнедельный срок на сборку и тестирование.
За эти деньги нужно построить систему, которая позволит работать с файлами небольшой группе в одной локальной сети с разных платформ (Windows, Mac OS). Требуется длительная работа без сисадмина на площадке, защита от отказов и базовые функции управления правами доступа.
Традиционные пути
Безусловно, можно купить сетевое хранилище: их делают
NetApp,
QNAP,
Synology и другие игроки, и притом делают неплохо даже для малого бизнеса. Но наши 500 евро – это только начало разговора для пустой коробки, без самих дисков. Если у вас есть 1000-2000 евро, лучше купите готовое изделие, а мы попробуем максимально заплатить знаниями и минимально — временем и деньгами.
UPD (спойлер ред. 2 от 2014-03-08):
Если собираете из нового железа, а не из хламаПо совокупности этого поста и его комментариев, любезно предоставленных хаброкомьюнити, предлагаю следующий алгоритм для простой
четырехдисковой системы:
- Если двойного размера самой ёмкой из доступных моделей диска не хватает для хранимых данных, прекращаем читать спойлер (пример: модель 4Тб, требуется хранить 7Тб данных, тогда продолжаем; если требуется хранить 10Тб, тогда прекращаем)
- Выбираем изделие из линейки MicroServer известного производителя серверов Харлампий-Панкрат; например, n36l, n40l, n54l, с четырьмя отсеками для дисков (главное, чтобы была поддержка ECC-памяти)
- Обязательно комплектуем наш сервер памятью с контролем четности (ECC) из расчета 1Гб на каждый 1Тб хранимых данных, но не менее 8Гб (по рекомендации FreeNAS для дисков до 4Тб получается как раз всего 8Гб)
- Если у нас нет ECC-памяти, немедленно прекращаем читать этот спойлер, читаем пост до конца
- Выбираем производителя дисков, используя актуальный обзор отказов; например, вот этот: http://habrahabr.ru/post/209894
- Выбираем недорогую линейку SATA дисков с обязательным наличием ERC, а зачем, читаем здесь: http://habrahabr.ru/post/92701
- Выбираем ёмкость дисков (2Тб, 3Тб или 4Тб) из расчета, что их будет четыре, и что доступной для данных будет только половина (вторая половина на избыточность RAID)
- Перед закупкой еще раз внимательно и досконально проверяем совместимость железа между собой, количества слотов, отсеков, планок и прочего, но для FreeNAS самое главное — поддержка всего железа актуальным ядром FreeBSD
- Выбираем хорошую загрузочную флэшку, прочитав продолжение данного поста (часть 2: хорошие воспоминания)
- Закупаем, вдыхаем ароматы нового железа, собираем, подключаем, запускаем; для ZFS обязательно выключаем все аппаратные RAID'ы
- Создаем том RAIDZ2 из четырех дисков, обязательно с двойной избыточностью (на размерах тома около 12Тб есть риск повстречать злобного URE, читайте о нем в этом посте; если мы не боимся URE и все-таки собираем RAIDZ на четырех дисках, проверяем размер физического сектора — на современных дисках он 4Кб, и в этом случае получится совершенно нелепый страйп 43Кб, который еще и просадит нам скорость массива: forums.servethehome.com/hard-drives-solid-state-drives/30-4k-green-5200-7200-questions.html)
- Соль, сахар, перец, jail'ы, шары, скрипты и тому подобную сметану добавляем по вкусу
А как же
облачное хранение, спросите вы? На момент написания этой статьи популярные облачные хранилища для наших объемов выглядят дороже, чем хотелось бы. Например, стоимость хранения неограниченного объема данных 36 месяцев на известном сервисе Брось Бокс обойдется в пару тысяч долларов с лишним, хотя и выплачивать их можно постепенно. Конечно, есть сервисы вроде
Amazon Glacier (благодарю А.М. за подсказку) или Ажурных Окон, но, во-первых, они тарифицируют не только хранение, но и обращение (как его априорно подсчитать?), а во-вторых не будем забывать, что бизнес сидит на Интернет-аплинке 10Мбит, и маневры терабайтами потребуют не только определенных усилий по управлению процессами, но и будут весьма утомительными для пользователей.
Обычно в таких случаях берут старый компьютер, докупают большие диски, ставят Linux (не обязательно, кто-то ухитряется и Windows 7), делают массив RAID5. Отлично. Всё работает хорошо примерно полгода-год, но одним солнечным утром сервер вдруг пропадает из сети без всякого предупреждения. Конечно, сисадмин уже давно работает в другой фирме (текучка кадров), резервной копии нет (объемы слишком велики), а новый сисадмин починить систему не может (при этом на чем свет стоит ругает старого сисадмина и диалект Linux YYY, ведь надо было использовать Linux ZZZ, тогда проблем бы точно не было). Все эти истории повторяются давно и одинаково, меняются только версии ОС и растут объемы данных.
Отраслевые мифы
Миф о RAID5
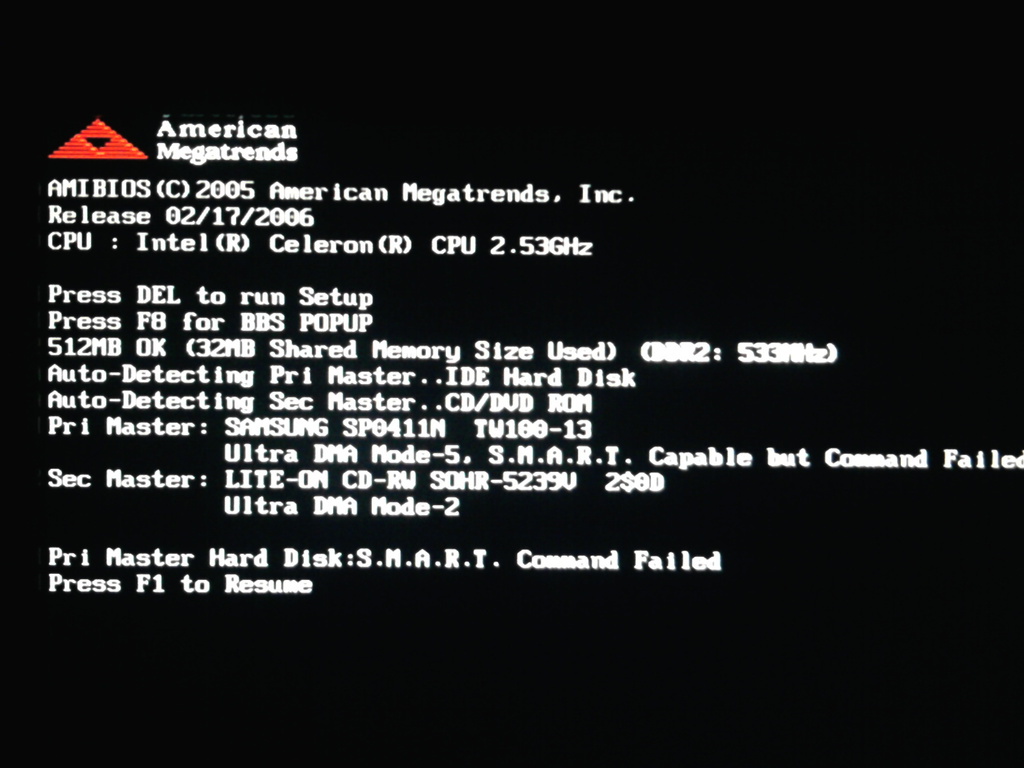
Самый распространенный миф, в который я и сам верил до недавнего времени – это то, что второго подряд отказа в массиве на практике не может быть по теории вероятности. А вот и может, да еще как! Смоделируем реальную ситуацию: сервер проработал пару лет, после чего в массиве отказывает диск. Пока ничего страшного, ставим новый диск, и что происходит? Ага, реконструкция массива, т.е. длительная максимальная нагрузка на уже порядком изношенные диски. В такой ситуации отказы очень даже возможны и происходят.
Но это не все. Есть еще заложенная производителем методическая вероятность ошибки чтения, которая при определенных обстоятельствах сейчас уже практически гарантирует, что RAID5 после отказа диска обратно не соберется.


 «Детали — это не детали. Они создают дизайн.» — Чарльз Имз.
«Детали — это не детали. Они создают дизайн.» — Чарльз Имз.



 Нет, названием я вовсе не хотел сказать, что это плохая технология, она наоборот прекрасна, но вот её реализации очень различаются. В интернете куча ресурсов, посвященных этой теме, и каждый считает своим долгом сделать сравнение, да еще с кучей графиков и официальных рекламаций. Чтож, значит это и мой долг. Вся разница в том, что мое сравнение будет включать в себя те аспекты, которые были значимы для меня (например проброс USB устройств в гостевые системы и удобство реализации программного роутера), а еще мне будет лень приводить официальные таблицы и значит мое сравнение будет короче, привязано к одной из практических задач. И самое главное — поскольку предприятие, в котором я работаю очень скупо на развитие IT инфраструктуры, то обсуждение будет вестись вокруг бесплатных продуктов. Итак, в ходе домашней и профессиональной деятельности пришлось столкнуться с такими системами, как VMWare vSphere, Microsoft Hyper-V и KVM. Рассмотрим их в порядке моего знакомства:
Нет, названием я вовсе не хотел сказать, что это плохая технология, она наоборот прекрасна, но вот её реализации очень различаются. В интернете куча ресурсов, посвященных этой теме, и каждый считает своим долгом сделать сравнение, да еще с кучей графиков и официальных рекламаций. Чтож, значит это и мой долг. Вся разница в том, что мое сравнение будет включать в себя те аспекты, которые были значимы для меня (например проброс USB устройств в гостевые системы и удобство реализации программного роутера), а еще мне будет лень приводить официальные таблицы и значит мое сравнение будет короче, привязано к одной из практических задач. И самое главное — поскольку предприятие, в котором я работаю очень скупо на развитие IT инфраструктуры, то обсуждение будет вестись вокруг бесплатных продуктов. Итак, в ходе домашней и профессиональной деятельности пришлось столкнуться с такими системами, как VMWare vSphere, Microsoft Hyper-V и KVM. Рассмотрим их в порядке моего знакомства: