
В комментариях к моему предыдущему топику об асинхронном программировании, коллбеках и использовании process.NextTick() в Node.js было задано немало вопросов о том, за счёт чего получается или может быть получена большая производительность при использовании неблокирующего кода. Постараюсь это наглядно показать :) Статья призвана в основном прояснить некоторые моменты работы Node.js (и libeio в его составе), которые на словах бывает трудно описать.
Пример обработки запросов сервером с блокирующим чтением:
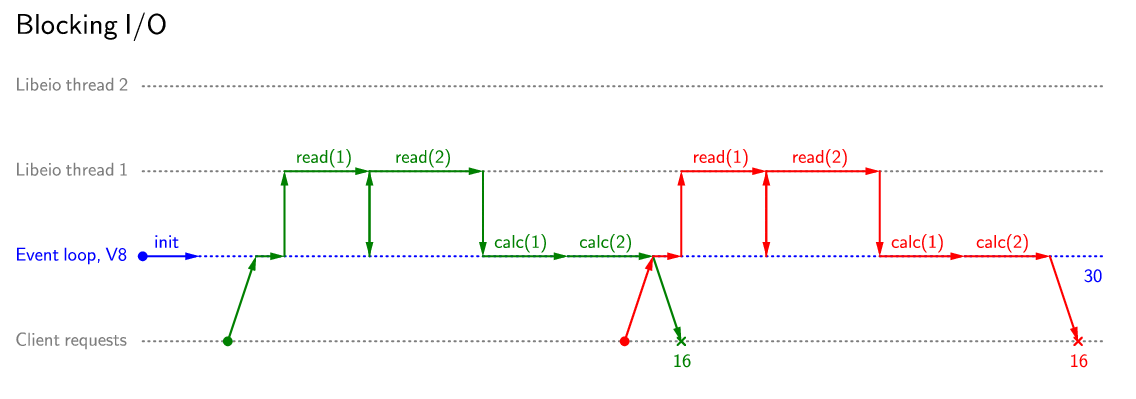
В первую очередь прокомментирую полезность использования неблокирующего ввода/вывода. Как правило, использовать блокирующие операции в Node.js стоит лишь на этапе инициализации приложения, и то не всегда. Правильная обработка ошибок в любом случае потребует использования try/catch, так что код при использовании неблокирующих операций не будет сложнее, чем при использовании блокирующих операций.
Нужно лишь помнить, что случае, когда запросов неблокирующих операций может оказаться больше, чем потоков libeio. В этом случае новые запросы будут становиться в очередь и блокировать выполнение, однако для программиста это будет происходить прозрачно.
Пример обработки запросов сервером с блокирующим чтением:
В первую очередь прокомментирую полезность использования неблокирующего ввода/вывода. Как правило, использовать блокирующие операции в Node.js стоит лишь на этапе инициализации приложения, и то не всегда. Правильная обработка ошибок в любом случае потребует использования try/catch, так что код при использовании неблокирующих операций не будет сложнее, чем при использовании блокирующих операций.
Нужно лишь помнить, что случае, когда запросов неблокирующих операций может оказаться больше, чем потоков libeio. В этом случае новые запросы будут становиться в очередь и блокировать выполнение, однако для программиста это будет происходить прозрачно.


 Библиотека jQuery — это общепризнанное средство манипуляции сразу несколькими форматами данных (XML, HTML, объекты DOM, обыкновенные объекты), да притом работающее посредством удобного (цепного) вызова методов с удобными (краткими) названиями. Поэтому ничуть не удивляют попытки приспособить jQuery не только к одному клиентскому, но также ещё и к серверному джаваскрипту — в частности, к Node.js.
Библиотека jQuery — это общепризнанное средство манипуляции сразу несколькими форматами данных (XML, HTML, объекты DOM, обыкновенные объекты), да притом работающее посредством удобного (цепного) вызова методов с удобными (краткими) названиями. Поэтому ничуть не удивляют попытки приспособить jQuery не только к одному клиентскому, но также ещё и к серверному джаваскрипту — в частности, к Node.js.