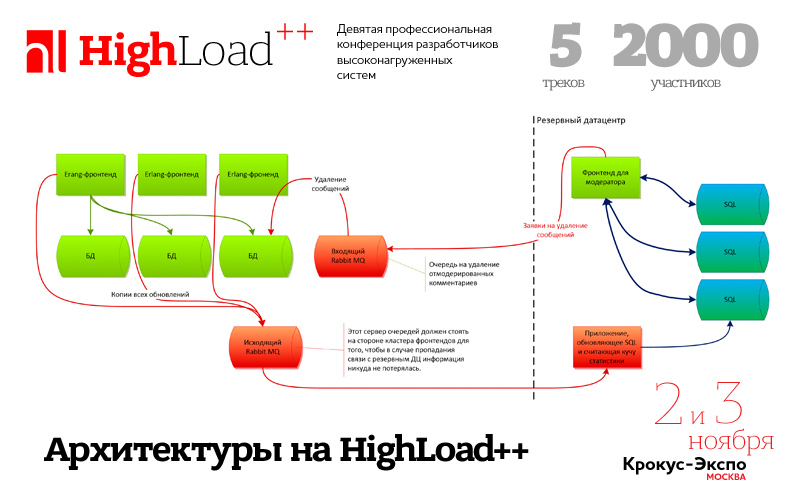
abstract: разница между текущей производительностью и производительностью теоретической; latency и IOPS, понятие независимости дисковой нагрузки; подготовка тестирования; типовые параметры тестирования; практическое copypaste howto.
Предупреждение: много букв, долго читать.
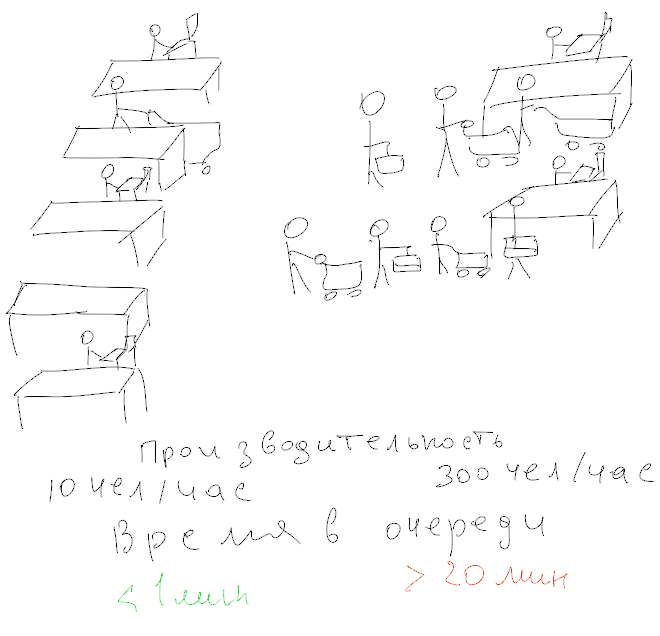
Очень частой проблемой, является попытка понять «насколько быстрый сервер?» Среди всех тестов наиболее жалко выглядят попытки оценить производительность дисковой подсистемы. Вот ужасы, которые я видел в своей жизни:
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.
Предупреждение: много букв, долго читать.
Лирика
Очень частой проблемой, является попытка понять «насколько быстрый сервер?» Среди всех тестов наиболее жалко выглядят попытки оценить производительность дисковой подсистемы. Вот ужасы, которые я видел в своей жизни:
- научная публикация, в которой скорость кластерной FS оценивали с помощью dd (и включенным файловым кешем, то есть без опции direct)
- использование bonnie++
- использование iozone
- использование пачки cp с измерениема времени выполнения
- использование iometer с dynamo на 64-битных системах
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.


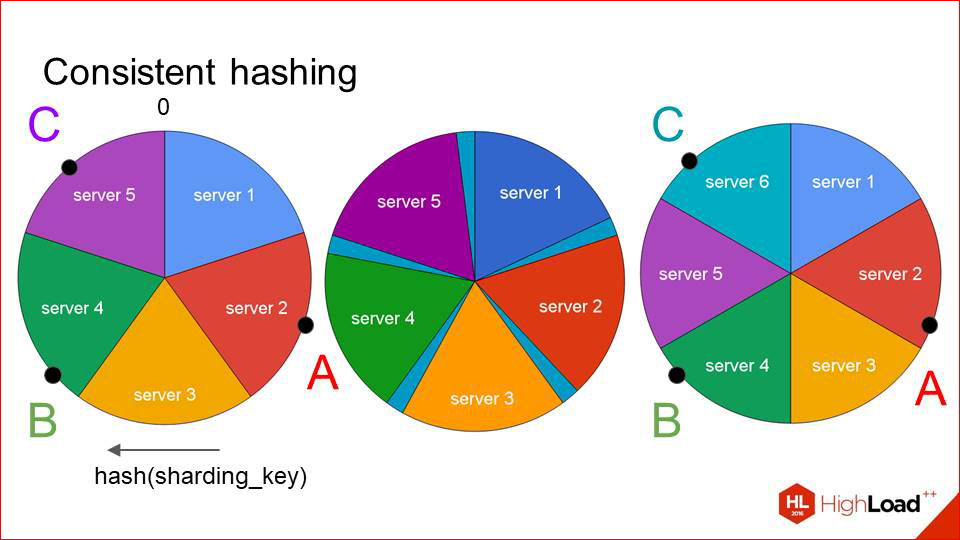












 Мы продолжаем посты с расшифровками выступлений на конференции
Мы продолжаем посты с расшифровками выступлений на конференции