Почему PostgreSQL тормозит: индексы и корреляция данных
12 мин
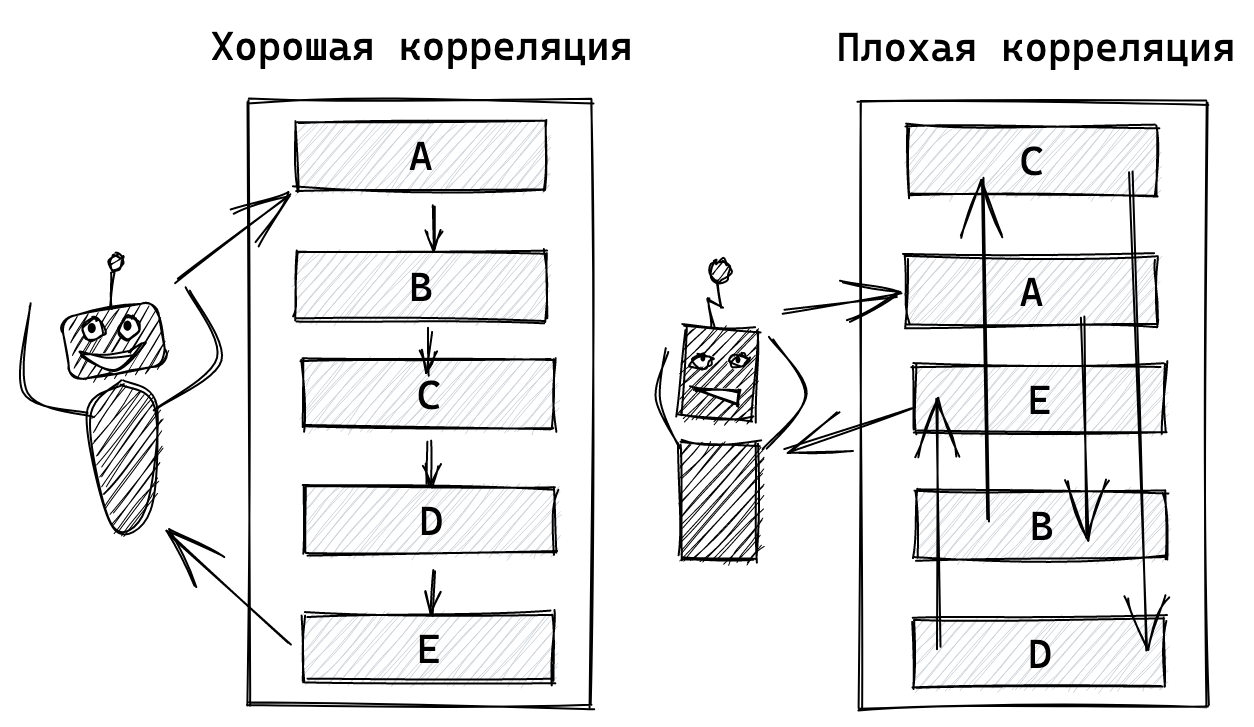
"Хочешь ускорить запросы, построй индекс" – классический первый шаг по увеличению производительности в PostgreSQL. Вот только на практике можно встретить ситуацию, когда индексы в PostgreSQL есть, но тормоза никуда не делись. Не все индексы являются эффективными. Одна из возможных причин тормозов индексов – это отсутствие корреляции данных. Давайте поговорим о пенальти на производительность, которое дает расположение данных: почему это происходит и как это можно предотвратить.





 Преподаватели готовы разделить с вами все таинства музыкальной теории но не раньше, чем вы научитесь читать эти закорючки самостоятельно.
Преподаватели готовы разделить с вами все таинства музыкальной теории но не раньше, чем вы научитесь читать эти закорючки самостоятельно.