GitHub hosts over 300 programming languages—from commonly used languages such as Python, Java, and Javascript to esoteric languages such as
Befunge, only known to very small communities.
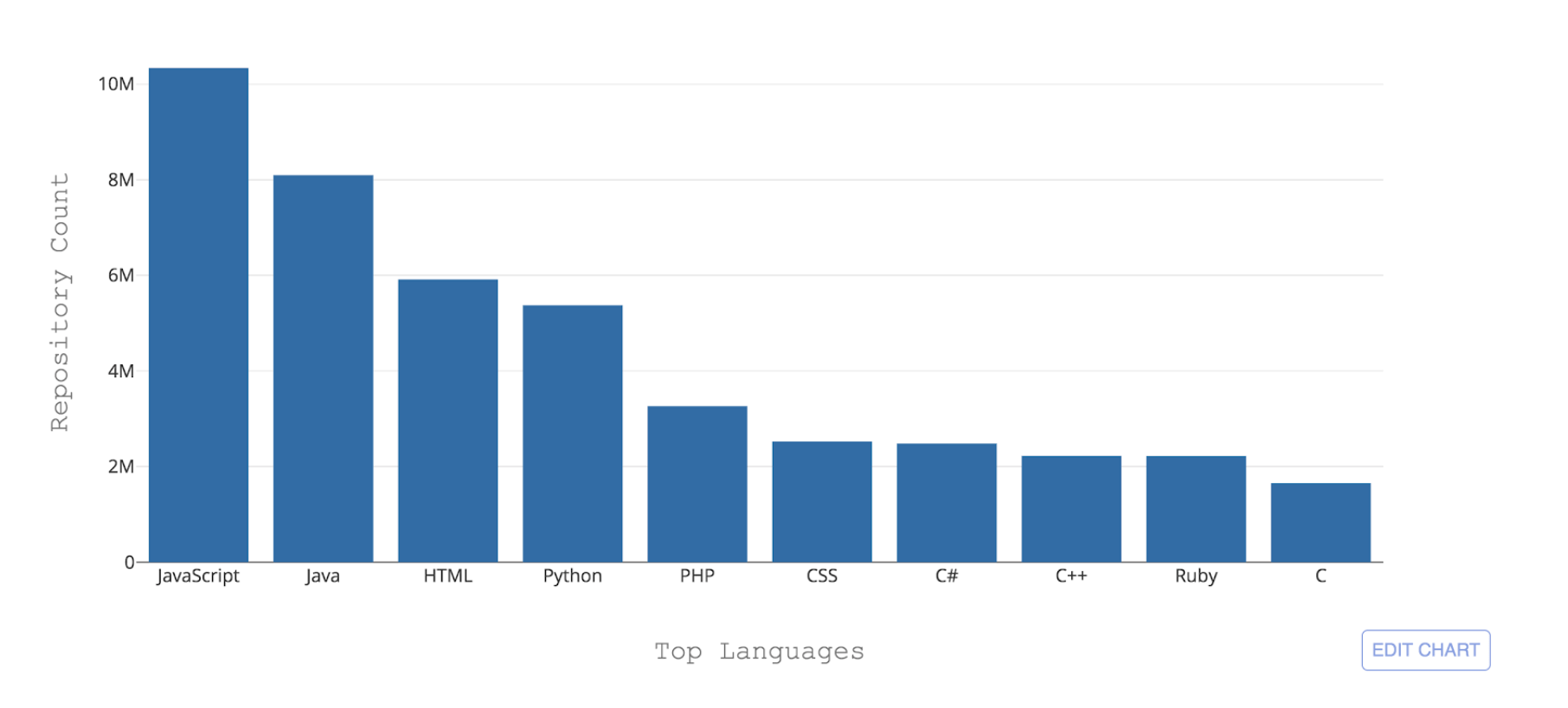 Figure 1: Top 10 programming languages hosted by GitHub by repository count
Figure 1: Top 10 programming languages hosted by GitHub by repository count
One of the necessary challenges that GitHub faces is to be able to recognize these different languages. When some code is pushed to a repository, it’s important to recognize the type of code that was added for the purposes of search, security vulnerability alerting, and syntax highlighting—and to show the repository’s content distribution to users.
Linguist is the tool we currently use to detect coding languages at GitHub. Linguist a Ruby-based application that uses various strategies for language detection, leveraging naming conventions and file extensions and also taking into account Vim or Emacs modelines, as well as the content at the top of the file (shebang). Linguist handles language disambiguation via heuristics and, failing that, via a Naive Bayes classifier trained on a small sample of data.
Although Linguist does a good job making file-level language predictions (84% accuracy), its performance declines considerably when files use unexpected naming conventions and, crucially, when a file extension is not provided. This renders Linguist unsuitable for content such as GitHub Gists or code snippets within README’s, issues, and pull requests.
In order to make language detection more robust and maintainable in the long run, we developed a machine learning classifier named OctoLingua based on an Artificial Neural Network (ANN) architecture which can handle language predictions in tricky scenarios. The current version of the model is able to make predictions for the top 50 languages hosted by GitHub and surpasses Linguist in accuracy and performance.