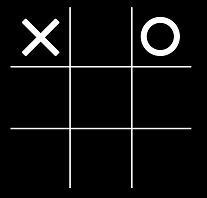
Алгоритм MiniMax. Использование минимакса в Unity на примере игры Поймай Овечку
Простой
14 мин
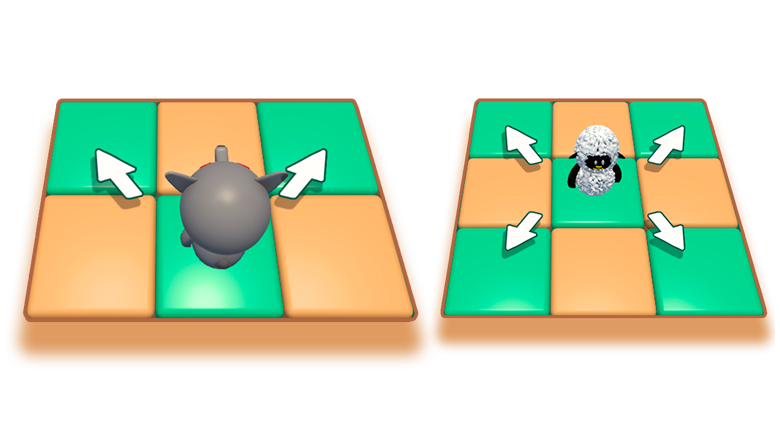
Минимакс - популярный алгоритм для принятия решений в играх с нулевой суммой (один выиграл - другой проиграл). Казалось бы, раз он так популярен, то всё что можно было про него сказать уже сказано? Не совсем. Информация сильно раздроблена, иногда ошибочна, а найти какие-либо примеры в играх довольно сложно. Поэтому в этой статье я постараюсь прояснить процесс разработки ИИ на основе минимакса для игры "Поймай Овечку".