В этой теме хотелось бы познакомить читателей с относительно новым подходом к контролю доступа под названием Attribute-based access control. Знакомство будет происходить на примере сравнения с популярным нынче Role-based access control.

Владислав Раструсный @FractalizeR
CTO
Встраиваем бэкдор в публичный ключ RSA
4 min
Tutorial

Привет, %username%!
Когда я увидел, как это работает, сказать, что я был в шоке — ничего не сказать. Это довольно простой трюк но после прочтения этой статьи вы больше никогда не будете смотреть на RSA по-прежнему. Это не взлом RSA, это нечто, что заставит вашу паранойю очень сильно разбухнуть.
Что нового в CSS селекторах 4-го уровня?
6 min
Recovery Mode
Это перевод поста "What's new in CSS selectors 4". Он показался мне интересным, и я решил перенести его на хабрахабр. P.S. Это мой первый перевод, не судите строго, и если увидите какие-то недочёты и ошибки — напишите пожалуйста в личку, я постараюсь исправить ошибки. Далее, со слов автора.
Пожалуйста, имейте ввиду, что данная статья описывает черновой вариант спецификации на январь 2015 года, что значит, что информация, изложенная в статье, без предупреждения может быть изменена.
CSS-селекторы четвёртого уровня — это следующее поколение спецификации CSS, последняя версия которой была выпущена в 2011 году, пробыв в течении нескольких лет в состоянии черновика.
Так что же нас ожидает нового?
Пожалуйста, имейте ввиду, что данная статья описывает черновой вариант спецификации на январь 2015 года, что значит, что информация, изложенная в статье, без предупреждения может быть изменена.
CSS-селекторы четвёртого уровня — это следующее поколение спецификации CSS, последняя версия которой была выпущена в 2011 году, пробыв в течении нескольких лет в состоянии черновика.
Так что же нас ожидает нового?
Неперсонализированные рекомендации: метод ассоциаций
5 min
Персональные рекомендации позволяют познакомить пользователя с объектами, о которых он, возможно, никогда не знал (и не узнал бы), но которые могут ему понравиться с учетом его интересов, предпочтений и поведенческих свойств. Однако, часто пользователь ищет не новый объект, а, к примеру, объект A похожий на объект B («Форсаж 2» похож на «Форсаж»), или объект A, который приобретается/потребляется с объектом B (сыр с вином, пиво с детским питанием, гречка с тушенкой и т.д.). Построить такие рекомендации позволяют неперсонализированные рекомендательные системы (НРС).
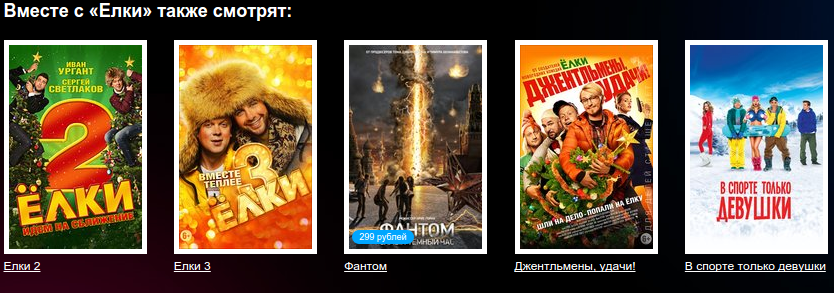
Рекомендовать похожие/сопутствующие объекты можно, ориентируясь на знания об объектах (свойства, теги, параметры) или на знания о действиях, связанных с объектами (покупки, просмотры, клики). Преимуществом первого способа является то, что он позволяет достаточно точно определить похожие по свойствам объекты («Форсаж 2» и «Форсаж» — похожие актеры, похожий жанр, похожие теги, ...). Однако данный способ не сможет порекомендовать сопутствующие объекты: сыр и вино. Еще одним недостатком этого способа является тот факт, что для разметки всех объектов, доступных на сервисе, требуется не мало усилий.
В то же время почти каждый сервис логирует информацию о том, какой пользователь просмотрел/купил/кликнул какой объект. Данной информации достаточно для построения НРС, которая позволит рекомендовать как похожие, так и сопутствующие объекты.
Под катом описан метод ассоциаций, позволяющий построить неперсонализированные рекомендации, основываясь лишь на данных о действиях над объектами. Там же код на Python, позволяющий применить метод для большого объема данных.
Рекомендовать похожие/сопутствующие объекты можно, ориентируясь на знания об объектах (свойства, теги, параметры) или на знания о действиях, связанных с объектами (покупки, просмотры, клики). Преимуществом первого способа является то, что он позволяет достаточно точно определить похожие по свойствам объекты («Форсаж 2» и «Форсаж» — похожие актеры, похожий жанр, похожие теги, ...). Однако данный способ не сможет порекомендовать сопутствующие объекты: сыр и вино. Еще одним недостатком этого способа является тот факт, что для разметки всех объектов, доступных на сервисе, требуется не мало усилий.
В то же время почти каждый сервис логирует информацию о том, какой пользователь просмотрел/купил/кликнул какой объект. Данной информации достаточно для построения НРС, которая позволит рекомендовать как похожие, так и сопутствующие объекты.
Под катом описан метод ассоциаций, позволяющий построить неперсонализированные рекомендации, основываясь лишь на данных о действиях над объектами. Там же код на Python, позволяющий применить метод для большого объема данных.
Обзор наиболее интересных материалов по анализу данных и машинному обучению №28 (22 — 28 декабря 2014)
4 min

Представляю вашему вниманию очередной выпуск обзора наиболее интересных материалов, посвященных теме анализа данных и машинного обучения.
Играем с генетическими алгоритмами
6 min
Одним субботним декабрьским вечером сидел я над книгой The Blind Watchmaker (Слепой Часовщик), как на глаза мне попался невероятно интересный эксперимент: возьмём любое предложение, например Шекспировскую строку: Methinks it is like a weasel и случайную строку такой же длины: wdltmnlt dtjbkwirzrezlmqco p и начнем вносить в неё случайные изменения. Через сколько поколений эта случайная строка превратится в Шекспировскую строку, если выживать будут лишь потомки более похожие на Шекспировскую?
Сегодня мы повторим этот эксперимент, но в уже совершенно другом масштабе.

Структура статьи:
Осторожно трафик!
Сегодня мы повторим этот эксперимент, но в уже совершенно другом масштабе.
Структура статьи:
- Что такое генетический алгоритм
- Почему это работает
- Формализуем задачу со случайной строкой
- Пример работы алгоритма
- Эксперименты с классикой
- Код и данные
- Выводы
Осторожно трафик!
15 лучших JavaScript-библиотек для построения диаграмм и сводных таблиц
6 min
Translation
Практически невозможно представить себе информационную панель без диаграмм и графиков. Они быстро и эффективно отображают сложные статистические данные. Более того, хорошая диаграмма также улучшает общий дизайн вашего сайта.
В этой статье я покажу вам некоторые из лучших JavaScript библиотек для построения диаграмм/схем (и сводных таблиц). Эти библиотеки помогут вам в создании красивых и настраиваемых графиков для ваших будущих проектов.
Хотя большинство библиотек являются бесплатными и свободно распространяемыми, для некоторых из них есть платные версии с дополнительным функционалом.
В этой статье я покажу вам некоторые из лучших JavaScript библиотек для построения диаграмм/схем (и сводных таблиц). Эти библиотеки помогут вам в создании красивых и настраиваемых графиков для ваших будущих проектов.
Хотя большинство библиотек являются бесплатными и свободно распространяемыми, для некоторых из них есть платные версии с дополнительным функционалом.
Почему вам НЕ стоит использовать AngularJs
12 min
Много времени прошло с момента появления AngularJs (в масштабах веб-технологий конечно). Сейчас в интернетах есть огромное количество постов восхваляющих этот фреймворк до небес, что это манна небесная не иначе, а критики не так уж и много как он того заслуживает. Но такие статьи уже потихоньку начинают появляться, и меня это радует, надеюсь индустрия переболеет ангуляром так же, как переболела MooTools, Prototype, %какой-нибудь новый язык под JVM%, %другая-супер-революционная-технология%. Не знаю почему, но в IT-области такие революционные технологии, которые поднимают шум, а потом пропадают, появляются довольно часто. Хороший разработчик должен уметь отличать очередную модную технологию, от работающего инструмента. И для этого очень важно критически смотреть на вещи. Моя статья — это компиляция самых весомых выводов из других статей, и моих личных умозаключений. Ангуляр создает хороший вау-эффект, когда видишь его впервые: «ух ты, я написал ng-repeat, и реализовал эту логику одними тегами и все само обновляется!», но как только приходится реализовывать реальные приложения, а не очередной TODO-лист, то все становиться очень печально. Сразу хочу сказать, что фреймворк я знаю хорошо, даже больше чем мне хотелось бы его знать, я программировал на нем в течении 2 лет. И для следующего проекта я его точно не выберу, и это хорошо, все мы учимся на ошибках. Так что же не так с ангуляром? Тут нет однозначного ответа, слишком много разных недостатков, которые создают такой облик фреймворку. Если одним словом – непродуманная архитектура. Под катом я привожу конкретику, так что устраивайтесь поудобнее. ДА НАЧНЕТСЯ ХОЛЛИ ВАР!
Сэм Альтман: Как сформировать команду и культуру стартапа?
31 min
Translation

Cтэнфордский курс CS183B: How to start a startup. Стартовал в 2012 году под руководством Питера Тиля. Осенью 2014 года прошла новая серия лекций ведущих предпринимателей и экспертов Y Combinator:
Вторая часть курса
Первая часть курса
- Сэм Альтман и Дастин Московитц: Как и зачем создавать стартап?
- Сэм Альтман: Как сформировать команду и культуру стартапа?
- Пол Грэм: Нелогичный стартап;
- Адора Чьюнг: Продукт и кривая честности;
- Адора Чьюнг: Стремительный рост стартапа;
- Питер Тиль: Конкуренция – удел проигравших;
- Питер Тиль: Как построить монополию?
- Алекс Шульц: Введение в growth hacking [1, 2, 3];
- Кевин Хейл: Тонкости в работе с пользовательским опытом [1, 2];
- Стэнли Тэнг и Уокер Уильямс: Начинайте с малого;
- Джастин Кан: Как работать с профильными СМИ?
- Андрессен, Конуэй и Конрад: Что нужно инвестору;
- Андрессен, Конуэй и Конрад: Посевные инвестиции;
- Андрессен, Конуэй и Конрад: Как работать с инвестором;
- Брайан Чески и Альфред Лин: В чем секрет культуры компании?
- Бен Сильберман и братья Коллисон: Нетривиальные аспекты командной работы [1, 2];
- Аарон Леви: Разработка B2B-продуктов;
- Рид Хоффман: О руководстве и руководителях;
- Рид Хоффман: О лидерах и их качествах;
- Кит Рабуа: Управление проектами;
- Кит Рабуа: Развитие стартапа;
- Бен Хоровитц: Увольнения, повышения и переводы по службе;
- Бен Хоровитц: Карьерные советы, вестинг и опционы;
- Эммет Шир: Как проводить интервью с пользователями;
- Эммет Шир: Как в Twitch разговаривают с пользователями;
- Хосейн Рахман: Как в Jawbone проектируют hardware-продукты;
- Хосейн Рахман: Процесс проектирования в Jawbone.
Disclaimer: осторожно, трафик (объемный материал + слайды лекции).
Сэм Альтман и Дастин Московитц: Как и зачем создавать стартап?
35 min
Translation

Cтэнфордский курс CS183B: How to start a startup. Стартовал в 2012 году под руководством Питера Тиля. Осенью 2014 года прошла новая серия лекций ведущих предпринимателей и экспертов Y Combinator:
Вторая часть курса
Первая часть курса
- Сэм Альтман и Дастин Московитц: Как и зачем создавать стартап?
- Сэм Альтман: Как сформировать команду и культуру стартапа?
- Пол Грэм: Нелогичный стартап;
- Адора Чьюнг: Продукт и кривая честности;
- Адора Чьюнг: Стремительный рост стартапа;
- Питер Тиль: Конкуренция – удел проигравших;
- Питер Тиль: Как построить монополию?
- Алекс Шульц: Введение в growth hacking [1, 2, 3];
- Кевин Хейл: Тонкости в работе с пользовательским опытом [1, 2];
- Стэнли Тэнг и Уокер Уильямс: Начинайте с малого;
- Джастин Кан: Как работать с профильными СМИ?
- Андрессен, Конуэй и Конрад: Что нужно инвестору;
- Андрессен, Конуэй и Конрад: Посевные инвестиции;
- Андрессен, Конуэй и Конрад: Как работать с инвестором;
- Брайан Чески и Альфред Лин: В чем секрет культуры компании?
- Бен Сильберман и братья Коллисон: Нетривиальные аспекты командной работы [1, 2];
- Аарон Леви: Разработка B2B-продуктов;
- Рид Хоффман: О руководстве и руководителях;
- Рид Хоффман: О лидерах и их качествах;
- Кит Рабуа: Управление проектами;
- Кит Рабуа: Развитие стартапа;
- Бен Хоровитц: Увольнения, повышения и переводы по службе;
- Бен Хоровитц: Карьерные советы, вестинг и опционы;
- Эммет Шир: Как проводить интервью с пользователями;
- Эммет Шир: Как в Twitch разговаривают с пользователями;
- Хосейн Рахман: Как в Jawbone проектируют hardware-продукты;
- Хосейн Рахман: Процесс проектирования в Jawbone.
CSS Font-Size: em vs. px vs. pt vs. percent
3 min
Translation
Одним из наиболее запутанных аспектов CSS является применение font-size атрибута для масштабирования текста. Используя CSS, вы можете изменить размер текста в браузере с помощью четырех разных единиц измерения. Какая из этих четырех единиц лучше всего подходит для веб? Это вопрос, который породил разнообразные дискуссии и критику. Поиск окончательного ответа затруднен, поскольку вопрос сам по себе сложный.
Архитектурный дизайн мобильных приложений
9 min
Признак плохого дизайна №1:
Наличие объекта-«бога» с именем, содержащим «Manager», «Processor» или «API»
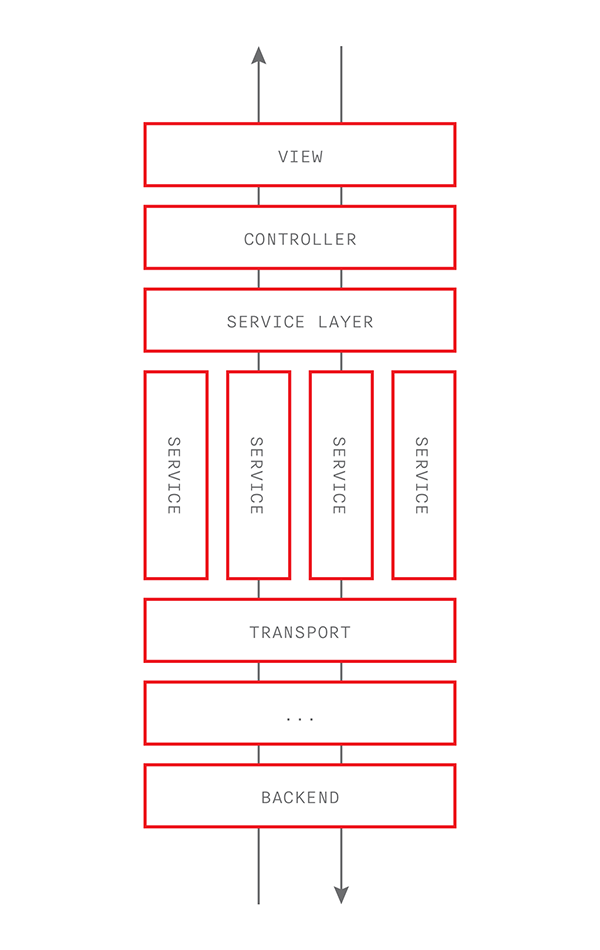
Ведущий iOS-разработчик Redmadrobot Егор BepTep Тафланиди — о том, как добиться стройного архитектурного дизайна мобильного приложения, используя классические шаблоны проектирования и логическое разделение исходного кода на модули.
Наличие объекта-«бога» с именем, содержащим «Manager», «Processor» или «API»
Ведущий iOS-разработчик Redmadrobot Егор BepTep Тафланиди — о том, как добиться стройного архитектурного дизайна мобильного приложения, используя классические шаблоны проектирования и логическое разделение исходного кода на модули.
Scapegoat-деревья
7 min
Tutorial
 Сегодня мы посмотрим на структуру данных, называемую Scapegoat-деревом. «Scapegoat», кто не в курсе, переводится как «козёл отпущения», что делает дословный перевод названия структуры каким-то странным, поэтому будем использовать оригинальное название. Деревьев поиска, как вы, возможно, знаете есть очень много разных видов, и в основе всех их лежит одна и та же идея: "А хорошо бы при поиске элемента перебирать не весь набор данных подряд, а только какую-то часть, желательно размера порядка log(N)".
Сегодня мы посмотрим на структуру данных, называемую Scapegoat-деревом. «Scapegoat», кто не в курсе, переводится как «козёл отпущения», что делает дословный перевод названия структуры каким-то странным, поэтому будем использовать оригинальное название. Деревьев поиска, как вы, возможно, знаете есть очень много разных видов, и в основе всех их лежит одна и та же идея: "А хорошо бы при поиске элемента перебирать не весь набор данных подряд, а только какую-то часть, желательно размера порядка log(N)". Для этого каждая вершина хранит ссылки на своих детей и какой-то критерий, по которому при поиске точно понятно, в какую из дочерних вершин надо перейти. За логарифмическое время это всё будет работать тогда, когда дерево является сбалансированным (ну или стремится к этому) — т.е. когда «высота» каждого из поддеревьев каждой вершины примерно одинакова. А вот способы балансировки дерева уже у каждого типа деревьев свои: в красно-чёрных деревьях в вершинах хранятся маркеры «цвета», подсказывающие когда и как нужно перебалансировать дерево, в АВЛ-деревьях в вершинах хранится разница высот детей, Splay-деревья ради балансировки вынуждены изменять дерево во время операций поиска и т.д.
Scapegoat-дерево тоже имеет свой подход к решению проблемы балансировки дерева. Как и для всех остальных случаев он не идеален, но вполне применим в некоторых ситуациях.
К достоинствам Scapegoat-дерева можно отнести:
- Отсутствие необходимости хранить какие-либо дополнительные данные в вершинах (а значит мы выигрываем по памяти у красно-черных, АВЛ и декартовых деревьев)
- Отсутствие необходимости перебалансировать дерево при операции поиска (а значит мы можем гарантировать максимальное время поиска O(log N), в отличии от Splay-деревьев, где гарантируется только амортизированное O(log N))
- Амортизированная сложность операций вставки и удаления O(log N) — это в общем-то аналогично остальным типам деревьев
- При построении дерева мы выбираем некоторый коэффициент «строгости» α, который позволяет «тюнинговать» дерево, делая операции поиска более быстрыми за счет замедления операций модификации или наоборот. Можно реализовать структуру данных, а дальше уже подбирать коэффициент по результатам тестов на реальных данных и специфики использования дерева.
К недостаткам можно отнести:
- В худшем случае операции модификации дерева могут занять O(n) времени (амортизированна сложность у них по-прежнему O(log N), но защиты от «плохих» случаев нет).
- Можно неправильно оценить частоту разных операций с деревом и ошибиться с выбором коэффициента α — в результате часто используемые операции будут работать долго, а редко используемые — быстро, что как-то не хорошо.
Конвейер обработки текста в Sphinx
10 min
Translation
Обработка текста в поисковом движке выглядит достаточно простой снаружи, однако на самом деле это сложный процесс. При индексации текст документов должен быть обработан стриппером HTML, токенайзером, фильтром стоп-слов, фильтром словоформ и морфологическим процессором. А ещё при этом нужно помнить про исключения (exceptions), слитные (blended) символы, N-граммы и границы предложений. При поиске всё становится ещё сложнее, поскольку помимо всего вышеупомянутого нужно вдобавок обрабатывать синтаксис запроса, который добавляет всевозможные спец. символы (операторы и маски). Сейчас мы расскажем, как всё это работает в Sphinx.
Упрощённо конвейер обработки текста (в движке версий 2.х) выглядит примерно так:

Выглядит достаточно просто, однако дьявол кроется в деталях. Есть несколько очень разных фильтров (которые применяются в особом порядке); токенайзер занимается ещё чем-то помимо разбиения текста на слова; и наконец под «и т.д.» в блоке морфологии на самом деле находится ещё по меньшей мере три разных варианта.
Поэтому более точной будет следующая картина:
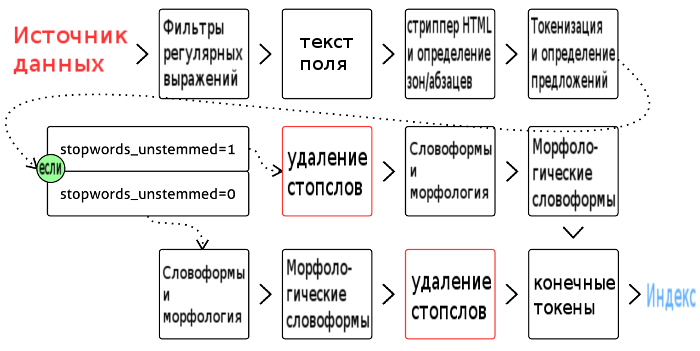
Картина в целом
Упрощённо конвейер обработки текста (в движке версий 2.х) выглядит примерно так:
Выглядит достаточно просто, однако дьявол кроется в деталях. Есть несколько очень разных фильтров (которые применяются в особом порядке); токенайзер занимается ещё чем-то помимо разбиения текста на слова; и наконец под «и т.д.» в блоке морфологии на самом деле находится ещё по меньшей мере три разных варианта.
Поэтому более точной будет следующая картина:
Разработка КП на создание сайта на боевом примере
22 min
Привет, Хабр! Недавно мы запустили большой образовательный спецпроект про продажи и маркетинг для студий и агентств. В его рамках я подготовил текст про подготовку коммерческого предложения на боевом примере — и хотел поделиться им с аудиторией Хабра.
Мы пишем много разных теоретических материалов, и меня часто спрашивают "Андрей, теория — это хорошо, ну а покажи, как должно выглядеть конкретное предложение, которое ты считаешь хорошим?". Этот текст — мой развернутый, почти на 20 страниц, ответ на этот вопрос.
Я выбрал кейс, максимально приближенный к реалиям — и в виде полу-художественного повествования провел своего лирического героя Бубликова по всем этапам подготовки КП и участия в тендере. Давайте начнем:
Итак, в рамках кейса мы представляем выдуманную компанию «Студия Бубликова», работаем в Москве, основаны в 2008 году, в нашем штате 17 человек, мы специализируемся на продакшн-услугах, работаем на UMI, для пары-тройки давних клиентов ведем контекст и немного SMM, работаем по средней ставке в 1700 руб./час, имеем хорошую поддержку (с выстроенными процессами и выделенными ресурсами). Мы есть в некоторых рейтингах веб-студий в середине списка, пару раз в год выступаем с докладами на среднего размера конференциях, позиционируемся как хороший продакшн второго эшелона с сильной поддержкой. Наши клиенты — сфера услуг, ecommerce, несколько добывающих компаний, пара агентств недвижимости. Делаем, в основном, корпоративные сайты, магазины, иногда промо-сайты. Сложные большие сервисы и порталы особо не умеем.
Я тот самый Бубликов, чьим именем названа наша студия.
Мы пишем много разных теоретических материалов, и меня часто спрашивают "Андрей, теория — это хорошо, ну а покажи, как должно выглядеть конкретное предложение, которое ты считаешь хорошим?". Этот текст — мой развернутый, почти на 20 страниц, ответ на этот вопрос.
Я выбрал кейс, максимально приближенный к реалиям — и в виде полу-художественного повествования провел своего лирического героя Бубликова по всем этапам подготовки КП и участия в тендере. Давайте начнем:
Итак, в рамках кейса мы представляем выдуманную компанию «Студия Бубликова», работаем в Москве, основаны в 2008 году, в нашем штате 17 человек, мы специализируемся на продакшн-услугах, работаем на UMI, для пары-тройки давних клиентов ведем контекст и немного SMM, работаем по средней ставке в 1700 руб./час, имеем хорошую поддержку (с выстроенными процессами и выделенными ресурсами). Мы есть в некоторых рейтингах веб-студий в середине списка, пару раз в год выступаем с докладами на среднего размера конференциях, позиционируемся как хороший продакшн второго эшелона с сильной поддержкой. Наши клиенты — сфера услуг, ecommerce, несколько добывающих компаний, пара агентств недвижимости. Делаем, в основном, корпоративные сайты, магазины, иногда промо-сайты. Сложные большие сервисы и порталы особо не умеем.
Я тот самый Бубликов, чьим именем названа наша студия.
freelance — you're doing it wrong!
39 min
Доброго времени суток уважаемые хаброжители, меня зовут Юра, и сегодня я поведаю вам о проблемах высокотехнологичного отпрыска удалённой работы — фриланса, а именно о разработке мобильных, десктопных и вэб-приложений, вёрстке и дизайне. Работаю я в этой сфере достаточно недавно, буквально с 2008го, и опыта хорошего и плохого у меня накопилось достаточно много. Цель данной публикации — показать разницу между простыми сотрудниками и фрилансерами, а также — показать основные организационные проблемы, которые возникают при разработке и проектировании программного обеспечения. Я надеюсь, что этот пост поможет прояснить некоторые производственные моменты, которые могли бы быть не совсем очевидны для разработчиков и их руководства.
Суждения в данной статье субъективны — сплошная концентрированная «отсебятинка».
Они основаны на моём личном опыте и опыте людей с которыми я общаюсь.
Суждения в данной статье субъективны — сплошная концентрированная «отсебятинка».
Они основаны на моём личном опыте и опыте людей с которыми я общаюсь.
Обзор алгоритмов сжатия графов
7 min
Данная работа описывает способы сжатия прежде всего социальных(графы связей между пользователями в социальных сетях) и Web-графов(графы ссылок между сайтами).
Большинство алгоритмов на графах хорошо изучены и спроектированы из расчета того, что возможен произвольный доступ к элементам графа, на данный момент размеры социальных графов превосходят RAM среднестатистической машины по размеру, но в тоже время легко умещаются на жестком диске. Компромисным вариантом являтся сжатие данных с возможностью быстрого доступа к ним определенных запросов. Мы сконцентрируемся на двух:
а) получить список ребер для определенной вершины
б) узнать соединяются ли 2 вершины.
Большинство алгоритмов на графах хорошо изучены и спроектированы из расчета того, что возможен произвольный доступ к элементам графа, на данный момент размеры социальных графов превосходят RAM среднестатистической машины по размеру, но в тоже время легко умещаются на жестком диске. Компромисным вариантом являтся сжатие данных с возможностью быстрого доступа к ним определенных запросов. Мы сконцентрируемся на двух:
а) получить список ребер для определенной вершины
б) узнать соединяются ли 2 вершины.
Руководство хакера по нейронным сетям. Глава 2: Машинное обучение. Бинарная классификация
4 min
Translation
Содержание:
В последней главе мы рассматривали схемы с реальными значениями, которые вычисляли сложные выражения своих исходных значений (проход вперед), а также мы смогли рассчитать градиенты этих выражений по оригинальным исходным значениям (обратный проход). В этой главе мы поймем, насколько полезным может быть этот довольно простой механизм в обучении машины.
Глава 1: Схемы реальных значений
Часть 1:
Часть 2:
Часть 3:
Часть 4:
Часть 5:
Часть 6:
Введение
Базовый сценарий: Простой логический элемент в схеме
Цель
Стратегия №1: Произвольный локальный поиск
Часть 2:
Стратегия №2: Числовой градиент
Часть 3:
Стратегия №3: Аналитический градиент
Часть 4:
Схемы с несколькими логическими элементами
Обратное распространение ошибки
Часть 5:
Шаблоны в «обратном» потоке
Пример "Один нейрон"
Часть 6:
Становимся мастером обратного распространения ошибки
Глава 2: Машинное обучение
В последней главе мы рассматривали схемы с реальными значениями, которые вычисляли сложные выражения своих исходных значений (проход вперед), а также мы смогли рассчитать градиенты этих выражений по оригинальным исходным значениям (обратный проход). В этой главе мы поймем, насколько полезным может быть этот довольно простой механизм в обучении машины.
Сети для самых маленьких. Часть десятая. Базовый MPLS
45 min
Сеть нашей воображаемой компании linkmeup растёт. У неё есть уже магистральные линии в различных городах, клиентская база и отличный штат инженеров, выросших на цикле СДСМ.
Но всё им мало. Услуги ШПД — это хорошо и нужно, но есть ещё огромный потенциальный рынок корпоративных клиентов, которым нужен VPN.
Думали ребята над этим, ломали голову и пришли к выводу, что никак тут не обойтись без MPLS.
Если мультикаст был первой темой, которая требовала некоторого перестроения понимания IP-сетей, то, изучая MPLS, вам точно придётся забыть почти всё, что вы знали раньше — это особенный мир со своими правилами.

Сегодня в выпуске:
А начнём мы с вопроса: «Что не так с IP?»
Но всё им мало. Услуги ШПД — это хорошо и нужно, но есть ещё огромный потенциальный рынок корпоративных клиентов, которым нужен VPN.
Думали ребята над этим, ломали голову и пришли к выводу, что никак тут не обойтись без MPLS.
Если мультикаст был первой темой, которая требовала некоторого перестроения понимания IP-сетей, то, изучая MPLS, вам точно придётся забыть почти всё, что вы знали раньше — это особенный мир со своими правилами.

Сегодня в выпуске:
- Что такое MPLS
- Передача трафика в сети MPLS
- Терминология
- Распространение меток
- — Методы распространение меток
- — — — DU против DoD
- — — — Ordered Control против Independent Control
- — — — Liberal Label Retention Mode против Conservative Label Retention Mode
- — — — PHP
- — Протоколы распространения меток
- — — — LDP
- — — — — Практика
- — — — Применение чистого MPLS в связке с BGP
- — — — RSVP-TE
- — — — — Практика
- — ВиО
- — Полезные ссылки
А начнём мы с вопроса: «Что не так с IP?»
Сети для Самых Маленьких. Микровыпуск №4. Погружение в IOU
10 min
 Продолжая, а точнее завершая обзор разнообразных эмуляторов оборудования Сisco Systems, я подробно остановлюсь на Cisco IOU (Cisco IOS on UNIX).
Продолжая, а точнее завершая обзор разнообразных эмуляторов оборудования Сisco Systems, я подробно остановлюсь на Cisco IOU (Cisco IOS on UNIX).Именно этот эмулятор содержит максимальное количество фич и минимальное количество ограничений по функционалу (напомню, что он не распространяется и допускается только использование сотрудниками Cisco).
Основные его преимущества в том что достаточно быстр и неплохо работает с канальным уровнем.
Если быть максимально точным, то IOU работает только под Solaris, а под Linux'ом запускается IOL, но все привыкли использовать одно общее название, поэтому и в статье я буду придерживаться общего названия.
Рассмотрим его от начала и до конца, от установки и до конфигурирования, а под занавес выпустим его в реальную сеть.