
Если ты пишешь Dockerfile, скорее всего, он работает. Но вопрос не в том, работает ли. Вопрос в другом: будет ли он работать через неделю, на другом сервере, в CI/CD, на чужом железе — и будет ли это безопасно?

User
Если ты пишешь Dockerfile, скорее всего, он работает. Но вопрос не в том, работает ли. Вопрос в другом: будет ли он работать через неделю, на другом сервере, в CI/CD, на чужом железе — и будет ли это безопасно?

Я, думаю, многие уже слышали о появившихся в .NET 6 Minimal API - легковесной замене контроллеров/MVC. Кто-то уже успел ознакомиться и задался вопросом: "Ваше API в 3 строчки, это, конечно, здорово, но как это будет работать в реальном проекте с сотнями эндпоинтов, кучей фильтров, аттрибутов, расширениями OpenAPI/Swagger и прочих радостях?"
В этой статье я хочу ответить на этот вопрос: пройдемся от основ, преимуществ, недостатков, и закончим нюансами работы и проблемами, которые обязательно возникнут при миграции с контроллеров на Minimal API в крупном проекте.
А забегая чуть вперед: если думаете, стоит ли переводить проект на Mini API, вот вам сразу полезная информация: они могут жить в проекте вместе, причем даже без дублирования инфраструктуры: не обязательно переводить все разом - подробнее под катом.
Бонусом, заменим SwaggerGen на реализацию OpenAPI от Microsoft.

С выходом .NET 9 пакет Swashbuckle.AspNetCore выпилили из шаблона Web API. Это означает, что при создании нового приложения ASP.NET Core Web API у нас больше нет привычного зеленого пользовательского интерфейса Swagger для тестирования endpoint-ов. В статье — краткий разбор, почему это произошло, и обзор альтернативы Scalar.

Привет, ценители фантастики! Это Мария Дзюмина, я пишу для команды спецпроектов МТС Диджитал. Недавно делала обзор новинок фантастики 2024 года и сразу захотелось узнать, что выйдет в 2025-м. Прошлый год был невероятно богат на тему ИИ, и я стала искать ее и в новом году. И (спойлер) ее там гораздо меньше. По крайней мере, в тех книгах, выход которых уже анонсировали издательства.
ИИ все-таки есть, но не на первом месте. Я собрала топ-10 книг ближайшего будущего и уже могу выделить главную тему фантастики-2025. Интересно, что она назревала еще в прошлом году. Добро пожаловать к обсуждению!

Необходимость переноса данных из одной среды в другую — задача, с которой разработчики сталкиваются достаточно часто. Например, для отправки таблиц из прода в среды для тестирования. Вместе с тем, такая «перезаливка» таблиц нередко превращается в настоящий квест, по ходу которого нужно не только гарантировать сохранность данных, но и исключить ошибки, связанные с человеческим фактором. Поэтому лучшей практикой является автоматизация переноса.
Меня зовут Евгений Грибков. Я ведущий программист в центре технологий VK. В этой статье мы рассмотрим одно из возможных решений создания скрипта перезаливки заданных таблиц из одной БД в другую на примере MS SQL.


Zod — это TypeScript библиотека для валидации и создания схем данных, позволяющая определять строгие типы на этапе разработки. Она значительно упрощает управление типами и обеспечивает безопасность данных в приложениях. В отличие от других решений для валидации данных, Zod написан на TypeScript и позволяет использовать строгую типизацию как на этапе компиляции, так и на этапе выполнения.
Для простых структур можно задать валидацию буквально в одной строке:

Давайте поговорим о том как нам обустроить Россию правильно нанимать людей и не задавать глупые вопросы на интервью.

В этой статье рассмотрены все паттерны проектирования из "Банды четырёх" с примерами на языке программирования C#. Для самых терпеливых имеются дополнительные паттерны.
Это первая статья из серии "Сто паттернов для разработки корпоративных программ". Следующие статьи будут посвящены паттернам из книг Мартина Фаулера и Роберта Нистрема.
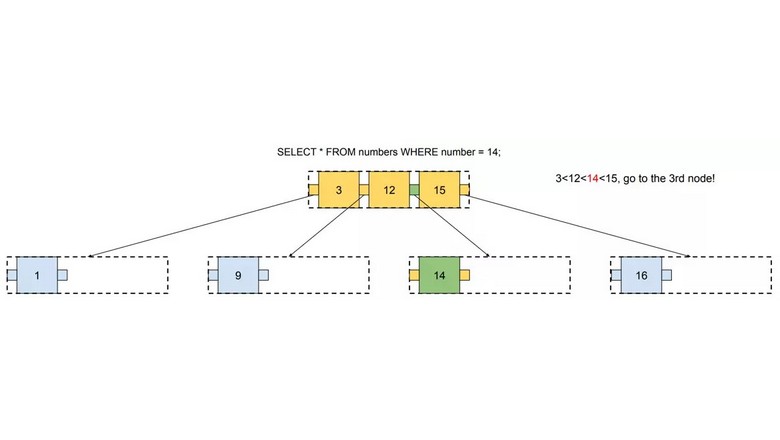
B-дерево — это структура, помогающая выполнять поиск в больших объёмах данных. Она была изобретена более сорока лет назад, однако по-прежнему используется в большинстве современных баз данных. Хотя существуют и более новые структуры индексов, например, LSM-деревья, B-дерево пока никто не победил в обработке большинства запросов баз данных.
После прочтения этого поста вы будете знать, как B-дерево упорядочивает данные и выполняет поисковые запросы.
В серии предыдущих статей я описывал, почему повсеместно используемые VPN- и прокси-протоколы такие как Wireguard и L2TP очень уязвимы к выявлению и могут быть легко заблокированы цензорами при желании, обозревал существующие гораздо более надежные протоколы обхода блокировок, клиенты для них, а также описывал настройку сервера для всего этого.
Но кое о чем мы не поговорили. Во второй статье я вскользь упомянул самую передовую и недетектируемую технологию обхода блокировок под названием XTLS-Reality, и пришло время рассказать о ней поподробнее, а именно - как настроить клиент и сервер для нее.
Кроме того, что этот протокол еще более устойчив к выявлению, приятным фактом будет и то, что настройка сервера XTLS-Reality гораздо проще, чем описанные ранее варианты - после предыдущих статей я получил довольно много комментариев типа "А что так сложно, нужен домен, нужны сертификаты, и куча всего" - теперь все будет гораздо проще.

В одной из моих предыдущих статей я рассказал о скрипте с названием GentleRebuild, который делал index rebuild в базах, работающих под нагрузкой 24/7, когда нет maintenance window, в Enterprise Edition. Там можно использовать опции ONLINE=ON и даже RESUMABLE=ON, вежливо уступая основной нагрузке базы.
А как же Standard Edition, где этого нет? Каюсь, раньше у меня в скрипте даже стояла проверка, и для Standard Edition скрипт сразу завершался. Но шеф меня попросил заняться и серверами со Standard Edition, и мне пришлось выжать из ситуации максимум.
Аргентум - язык программирования, построенный на новой ссылочной модели, которая не использует сборщик мусора и гарантирует отсутствие утечек памяти.

Автоматическая сборка мусора упрощает разработку программ, избавляя от необходимости отслеживать жизненный цикл объектов и удалять их вручную. Однако, чтобы сборщик мусора был полезным инструментом, а не главным врагом на пути к высокой производительности — иногда имеет смысл помогать ему, оптимизируя частые аллокации и аллокации больших объектов.
Для уменьшения аллокаций в современном .NET предусмотрены Span/Memory<T>, stackalloc с поддержкой Span, структуры и другие средства. Но если без объекта в куче не обойтись, например, если объект слишком большой для стека, или используется в асинхронном коде — этот объект можно переиспользовать. И для самых крупных объектов — массивов, в .NET встроены несколько реализаций ArrayPool<T>.
В этой статье я расскажу о внутреннем устройстве реализаций ArrayPool<T> в .NET, о подводных камнях, которые могут сделать пулинг неэффективным, о concurrent-структурах данных, а также о пулинге объектов, отличных от массивов.
Хабр, привет!
Сегодня я предлагаю совершить небольшое исследование на тему "как нам обустроить интеграционное тестирование и встроить его в сиайку".
Написать эту заметку меня сподвигла дискуссия, случившаяся недавно на работе. Инициативная группа "четырехглазых в свитерах" пыталась родить меры по улучшению качества нашего изделия и снижения трудозатрат QA-инженеров на проведение рутинного регрессионного тестирования. Как это часто бывает, разработчики если и писали тесты, то только модульные, оставляя интеграционные и end-to-end для тестировщиков. Для выполнения интеграционного тестирования QA-инженеры используют "тестовый стенд", на котором развернуты компоненты приложения (еще около 40, с позволения сказать, "микросервисов"), сервер базы данных (с не всегда ясным наполнением этой самой базы), брокер сообщений (RabbitMQ) и все остальное, что может потребоваться для запуска приложения. На этот тестовый стенд натравливаются автотесты, которые шатают приложение за все доступные снаружи конечные точки, таблицы БД и элементы UI пытаясь проверить максимальное количество тестовых сценариев в границах (и за ними!) возможных входных данных.
C постепенным переходом проектов на .NET Core фреймворки все большую популярность набирает стандартная реализация внедрения зависимостей от Microsoft. При использовании любого фреймворка для внедрения зависимостей рано или поздно разработчики сталкиваются с проблемой забытой или неправильной регистрации зависимостей, что влечет за собой ошибку в рантайме приложения. В этой статье разбираемся как покрыть unit-тестами внедрение зависимостей стандартной библиотеки Microsoft.Extensions.DependencyInjection.

Читатели по-разному относятся к международным литературным премиям и получившим их книгам. Кто-то прицельно следит за длинными и короткими списками, а кто-то считает, что премии слишком сильно ориентированы на модные веяния. И все же, думается, все согласятся с тем, что случаи, когда премии получает не один, а все романы в цикле, крайне редки и могут служить маркером высокого качества такого цикла и его большой значимости для того или иного жанра. А некоторые из них даже являются родоначальниками новых направлений в рамках фантастики. И вот несколько примеров таких серий, в которых каждый том становился лауреатом престижных наград.

5 лет назад мы форкнули Manticore из open source версии некогда популярного open source поискового движка Sphinx 2.3.2. У нас было два пакетика травы, семьдесят пять ампул мескалина, три C++ разработчика, один саппорт-инженер, опытный пользователь, менеджер, мать пятерых детей, помогающая нам на полставки и гора багов, крэшей и технических долгов. И вот, по прошествии 5 лет и сотен новых пользователей мы готовы сказать, что Manticore можно использовать как альтернативу Elasticsearch и для полнотекстового поиска и для аналитики данных.
В этой статье хочется: вспомнить как всё начиналось и что было до SOLR и Elasticsearch, максимально объективно обрисовать текущую ситуацию, попытаться понять куда нам двигаться дальше.

Пространственно-временно́й континуум обходится одним временны́м и тремя пространственными измерениями. M-теория струн расширяет физическую модель до невообразимых девяти пространственных измерений, но сохраняет время линейным.
В отличие от точных наук, учебники английской грамматики используют парадигму двухмерного времени, безжалостно разбивая наши попытки осмысления подобного представления о традиционную таблицу времён размером три на четыре.