
Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce
6 мин
Туториал

Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.







 Все слышали выражение “чёрным по белому написано”. Пришло оно к нам из бумажного мира и как-бы утверждает, что именно это сочетание цветов для текста и фона дает наилучший контраст и читабельность. Предлагаю опровергнуть это предположение и чаще пользоваться противоположной цветовой схемой. В этой статье я не буду убеждать в целесообразности цветового решения “белым по чёрному” (и некоторые утверждения могут быть спорными). Цель этой статьи сделать обзор инструментов, которые позволяют быстро и удобно инвертировать яркие цвета в часто используемых приложениях с целью уменьшить нагрузку на глаза. А также предлагаю инвертировать упомянутое выражение и в эпоху ЖК дисплеев говорить “белым по чёрному
Все слышали выражение “чёрным по белому написано”. Пришло оно к нам из бумажного мира и как-бы утверждает, что именно это сочетание цветов для текста и фона дает наилучший контраст и читабельность. Предлагаю опровергнуть это предположение и чаще пользоваться противоположной цветовой схемой. В этой статье я не буду убеждать в целесообразности цветового решения “белым по чёрному” (и некоторые утверждения могут быть спорными). Цель этой статьи сделать обзор инструментов, которые позволяют быстро и удобно инвертировать яркие цвета в часто используемых приложениях с целью уменьшить нагрузку на глаза. А также предлагаю инвертировать упомянутое выражение и в эпоху ЖК дисплеев говорить “белым по чёрному 

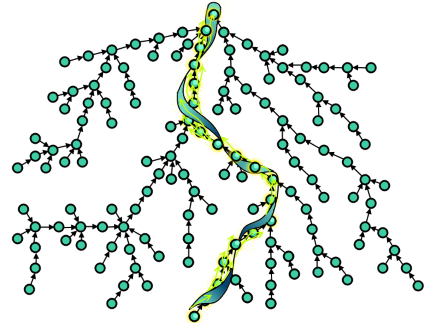 Речь пойдёт о простой структуре данных — системе непересекающихся множеств. Вкратце: даны непересекающиеся множества (например, компоненты связности графа) и по двум элементам x и y можно: 1) узнать, находятся ли x и y в одном множестве; 2) объединить множества, содержащие x и y. Сама структура очень проста в реализации и описывалась много раз в различных местах (например, есть хорошая статья на
Речь пойдёт о простой структуре данных — системе непересекающихся множеств. Вкратце: даны непересекающиеся множества (например, компоненты связности графа) и по двум элементам x и y можно: 1) узнать, находятся ли x и y в одном множестве; 2) объединить множества, содержащие x и y. Сама структура очень проста в реализации и описывалась много раз в различных местах (например, есть хорошая статья на 