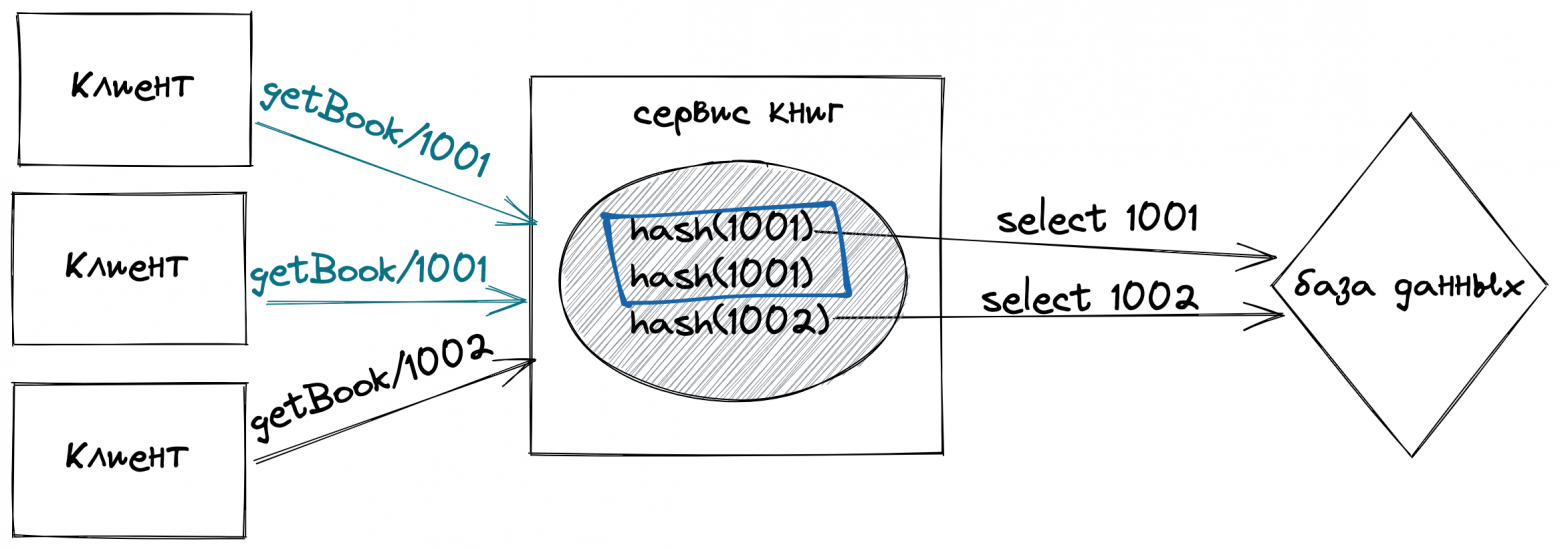
Технологии виртуализации приобрели популярность во всех отраслях экономики, и образовательная сфера — не исключение. Это вполне закономерно, поскольку именно в учебных заведениях раскрываются все преимущества использования виртуальных вычислений.
В этом посте мы рассмотрим наиболее важные эффекты от применения виртуализации в образовательных учреждениях.
Особенности ИТ в учебных заведениях
Работа ИТ-персонала в учебных заведениях имеет ряд отличий от аналогичного процесса в обычных компаниях и организациях.
Первое отличие — это фактор непредсказуемости в виде студентов и школьников. Из любопытства, по незнанию или поддавшись на «слабо», они могут запустить на школьном компьютере вредоносное ПО, изменить сетевые настройки, а при сильном желании — привести систему в нерабочее состояние. Ситуацию осложняет еще и тот факт, что все эти действия могут выполняться в рамках учебного процесса, если, например, речь идет о дисциплинах «Системное администрирование» или «Защита информации». А если все студенты, как это часто бывает, работают под одной «учебной» учеткой, невозможно даже понять, кто и зачем сказал «мяу» отформатировал диск.
Второе отличие школьных и вузовских систем — обилие устаревшего оборудования и операционных систем. Не так много учебных заведений имеют возможность регулярно обновлять компьютеры и приобретать лицензии на ОС и ПО для учебного процесса.
Третье отличие — сравнительно более низкая квалификация ИТ-персонала, функции которого часто возлагают на преподавателей профильных дисциплин, более-менее подкованных студентов-старшекурсников или аспирантов.