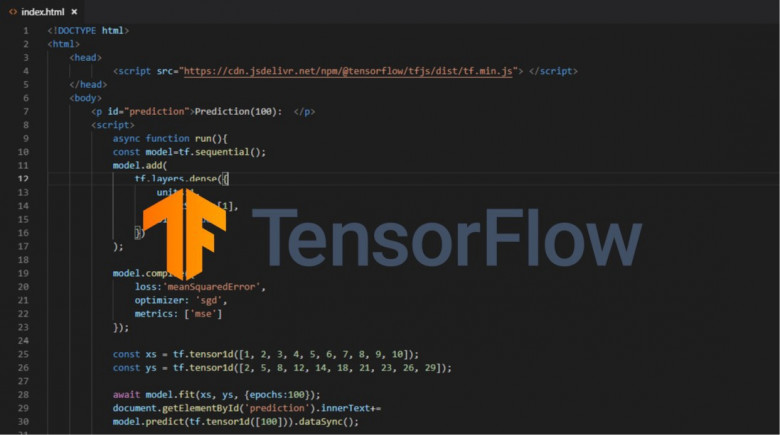
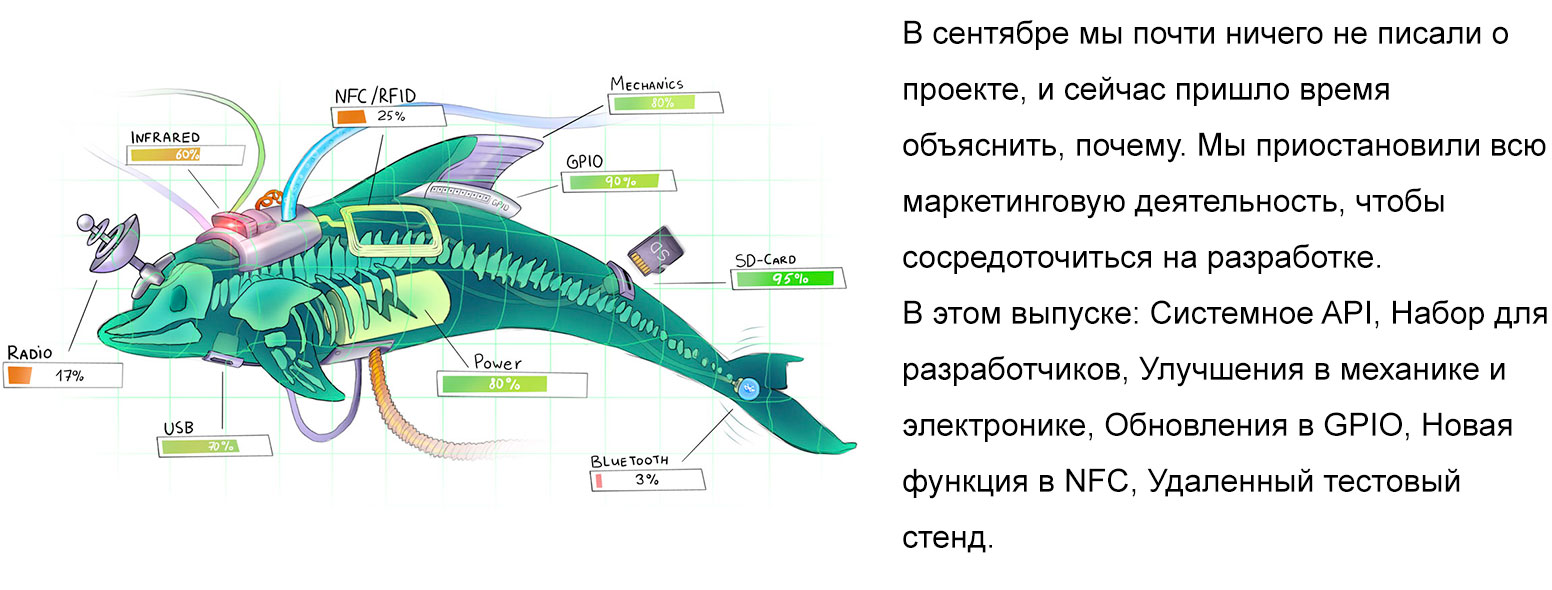
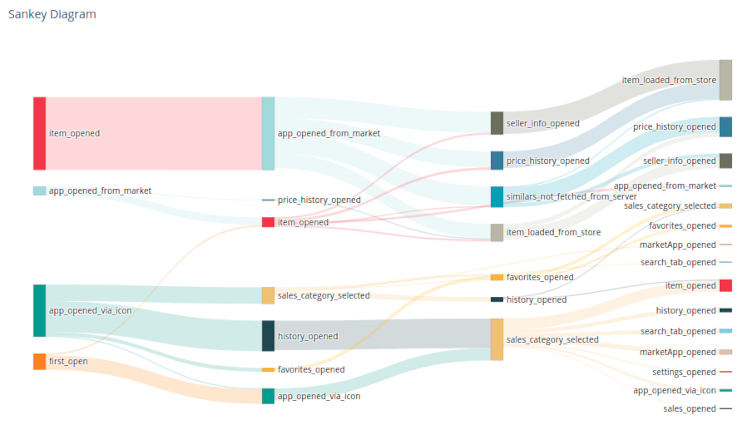
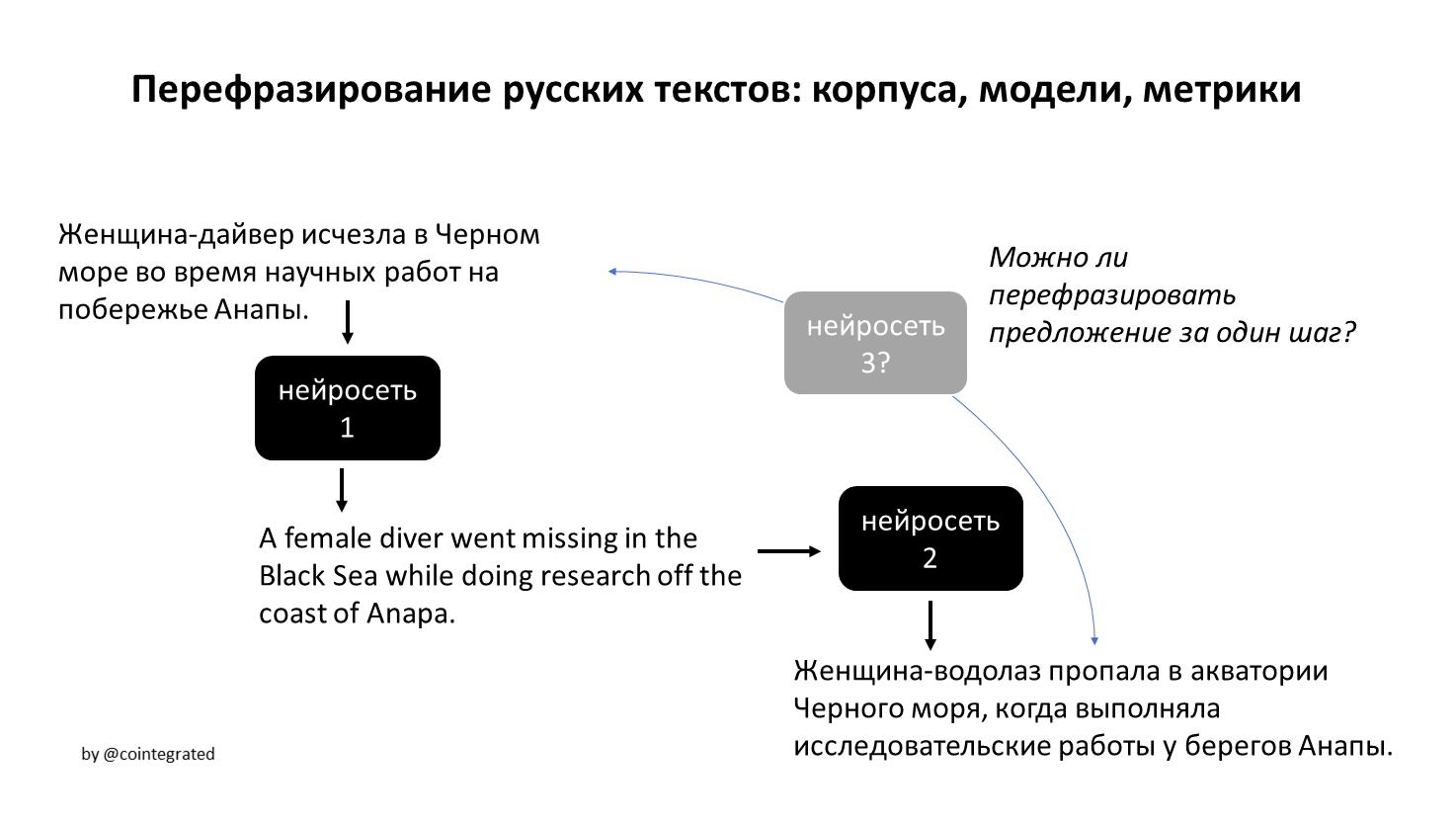
В современном мире часто приходится сталкиваться с проблемой рекомендации товаров или услуг пользователям какой-либо информационной системы. В старые времена для формирования рекомендаций обходились сводкой наиболее популярных продуктов: это можно наблюдать и сейчас, открыв тот же Google Play. Но со временем такие рекомендации стали вытесняться таргетированными (целевыми) предложениями: пользователям рекомендуются не просто популярные продукты, а те продукты, которые наверняка понравятся именно им. Не так давно компания Netflix проводила конкурс с призовым фондом в 1 миллион долларов, задачей которого стояло улучшение алгоритма рекомендации фильмов (подробнее). Как же работают подобные алгоритмы?
В данной статье рассматривается алгоритм коллаборативной фильтрации по схожести пользователей, определяемой с использованием косинусной меры, а также его реализация на python.

В данной статье рассматривается алгоритм коллаборативной фильтрации по схожести пользователей, определяемой с использованием косинусной меры, а также его реализация на python.