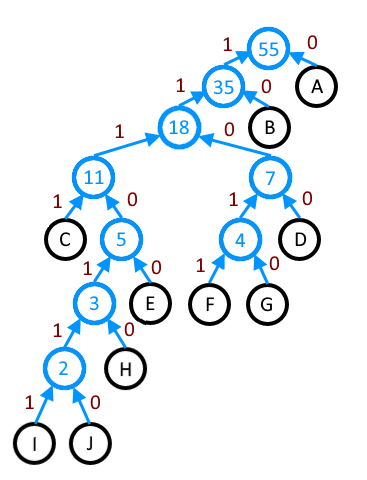
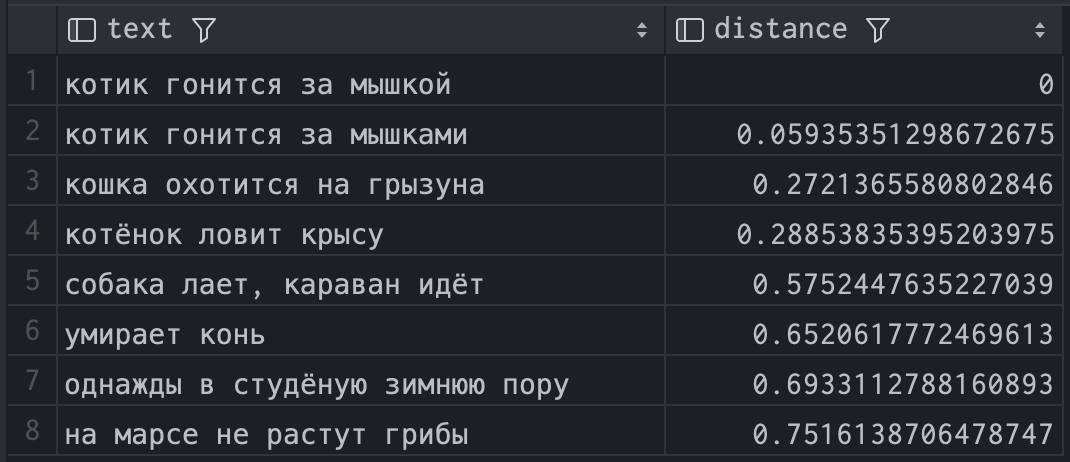
Присаживайтесь поудобнее и послушайте стариковскую байку: что случилось, когда я попросил у Rust слишком многого.
Допустим, вы хотите написать на Rust новую библиотеку. Всё, что для этого требуется — обернуть её в публичный API, через который будет предоставляться доступ к какому-то другому продукту, например, в Spotify API или, может быть, в API базы данных, скажем, ArangoDB. Не так это и тяжело: в конце концов, вы не изобретаете ничего нового, вам не приходится иметь дело со сложными алгоритмами. Поэтому вы полагаете, что задача решается относительно прямолинейно.
Вы решаете реализовать библиотеку с применением async. Работа, которая будет выполняться с помощью вашей библиотеки, заключается в основном в выполнении HTTP-запросов, обслуживающих ввод/вывод, поэтому применять здесь async действительно целесообразно (кстати, это одна из тех фишек, благодаря которым сегодня так востребован Rust). Вы садитесь писать код — и вот, через несколько дней у вас готова версия v0.1.0. «Приятно», — думаете вы, как только cargo publish заканчивается успешно и загружает вашу работу на crates.io.
Проходит несколько дней, и вам прилетает новое уведомление с GitHub. Оказывается, кто-то открыл тему: