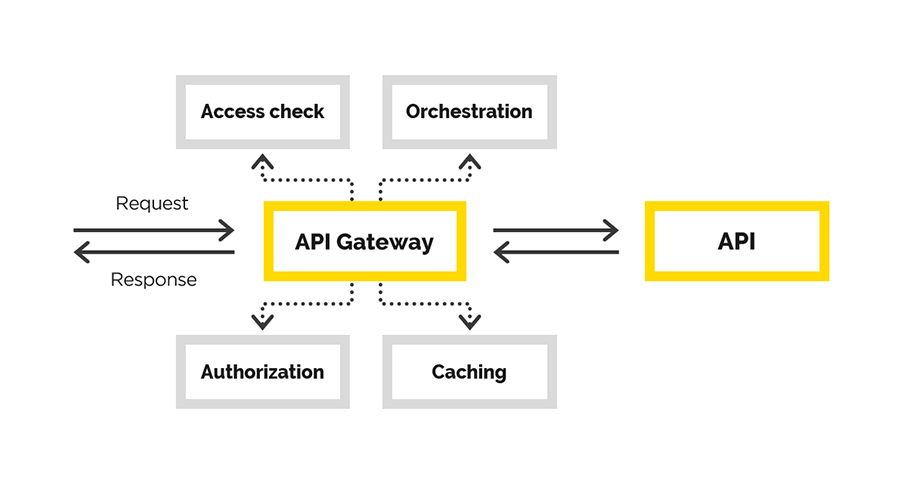
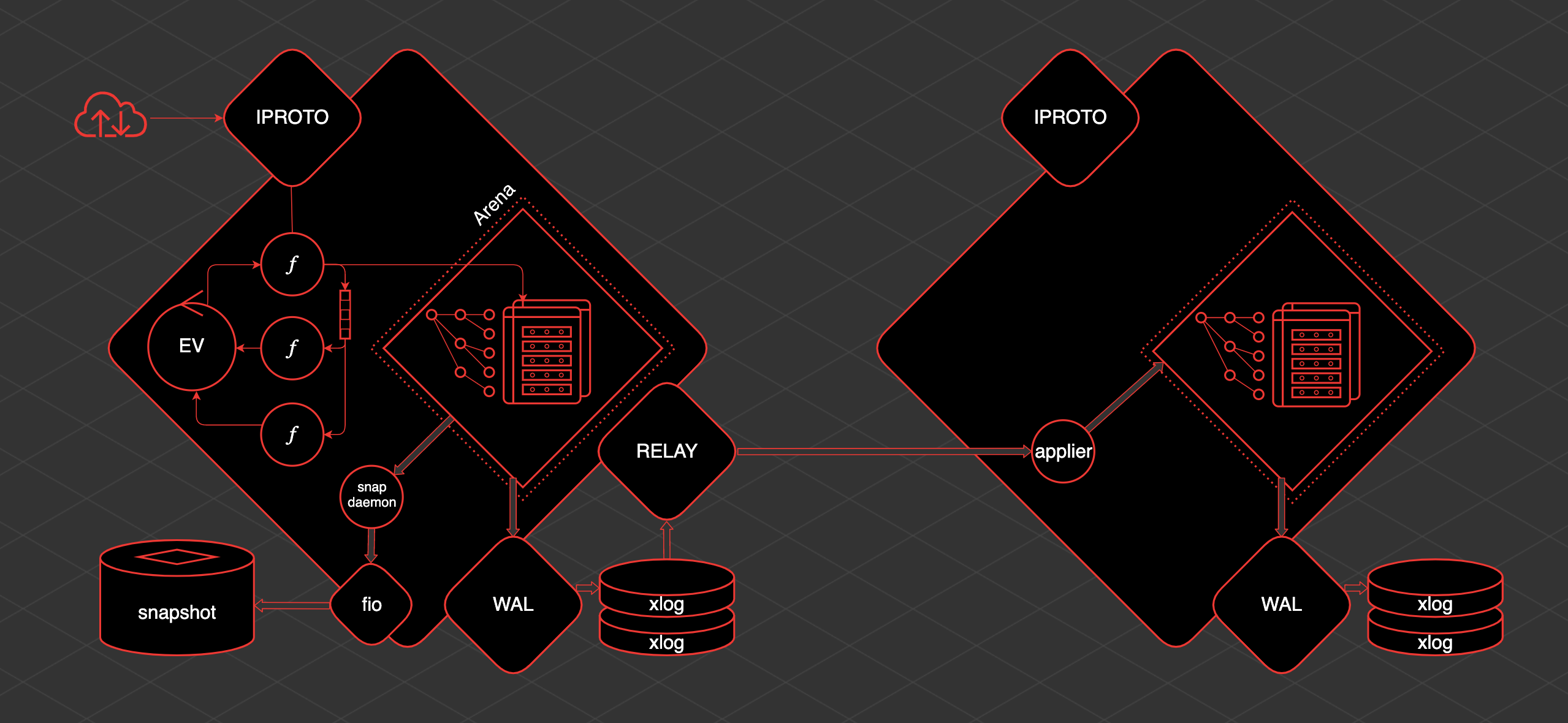
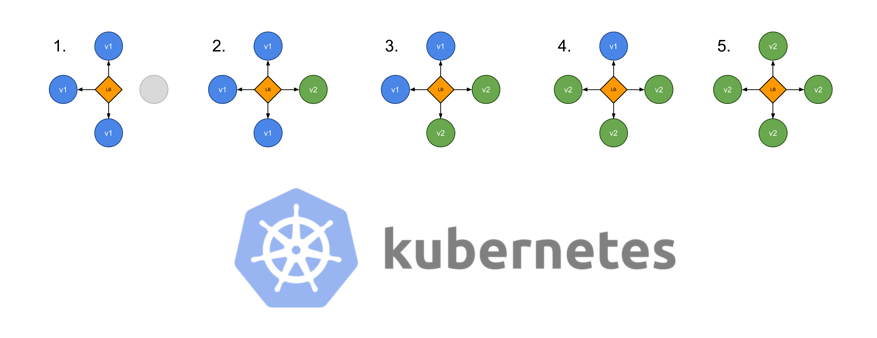
Сегодня мы выложили в опенсорс систему управления базами данных YDB — плод многолетнего опыта Яндекса в разработке систем хранения и обработки данных. Исходный код, документация, SDK и все инструменты для работы с базой опубликованы на GitHub под лицензией Apache 2.0. Развернуть базу можно как на собственных, так и на сторонних серверах — в том числе в любых облачных сервисах.

YDB решает задачи в одной из самых критичных областей — позволяет создавать интерактивные приложения, которые можно быстро масштабировать по нагрузке и по объёму данных. Мы разрабатывали её, исходя из ключевых требований к сервисам Яндекса. Во-первых, это катастрофоустойчивость, то есть возможность продолжить работу без деградации при отключении одного из дата-центров. Во-вторых, это масштабируемость на десятки тысяч серверов на чтение и на запись. В-третьих, это строгая консистентность данных.
В посте я расскажу об истории развития технологий баз данных, о том, зачем использовать YDB, как её применяют текущие пользователи и какие плюсы для всех несёт выход в опенсорс. А во второй половине поста поговорим о разных вариантах развёртывания.
YDB решает задачи в одной из самых критичных областей — позволяет создавать интерактивные приложения, которые можно быстро масштабировать по нагрузке и по объёму данных. Мы разрабатывали её, исходя из ключевых требований к сервисам Яндекса. Во-первых, это катастрофоустойчивость, то есть возможность продолжить работу без деградации при отключении одного из дата-центров. Во-вторых, это масштабируемость на десятки тысяч серверов на чтение и на запись. В-третьих, это строгая консистентность данных.
В посте я расскажу об истории развития технологий баз данных, о том, зачем использовать YDB, как её применяют текущие пользователи и какие плюсы для всех несёт выход в опенсорс. А во второй половине поста поговорим о разных вариантах развёртывания.

 при сортировке слиянием. Или переход от линейной сложности к логарифмической, при реализации поиска элемента в отсортированном массиве (см. бинарный поиск).
при сортировке слиянием. Или переход от линейной сложности к логарифмической, при реализации поиска элемента в отсортированном массиве (см. бинарный поиск).