
User

Интерпретируемость в машинном обучении: итоги 2021 г

В 2021-2022 годах уже ни для кого не секрет, что понимать логику работы моделей машинного обучения важно и нужно. Иначе можно насобирать множество проблем: от того, что модель не будет принята конечным пользователем, потому что непонятна, до того, что она будет работать неправильно, а поймем мы это уже слишком поздно.
Для интерпретируемости в машинном обучении устоялись термины Interpretable ML и Explainable AI (XAI). Объединяет их одно - стремление сделать модели машинного обучения понятными для конечного пользователя.
Под катом поговорим о том, что интересного произошло в интерпретируемости в 2021 г.
Как выбрать куда иммигрировать. 10 главных критериев
Сейчас многим как никогда нужен совет бывалого иммигранта в том, как выбрать место для переезда. А у меня, пожалуй, самый большой нетворк среди русскоязычных IT-иммигрантов от Канады до Чили, от Австралии до Португалии (можем померяться ?), да и сама я уже больше 6 лет живу в Кремниевой долине, а последние 3 занимаюсь релокейтом IT-специалистов в США. В общем наконец у меня появился повод собрать все знания и структурировать их в серию статей. Выкладывать буду раз в неделю. Анонс смотрите ниже (по мере публикации ссылки будут становиться кликабельными).
Few-shot-learning и другие страшные слова в классификации текстов

“Не значил он анапеста от анапеста,
как мы ни колотились отличить.”
nevmenandr (https://github.com/nevmenandr)
В настоящий момент количество курсов, на которых вы сможете получить знания, необходимые для трудоустройства по специальности «Аналитик данных» (Data Scientist, ML Engineer), растет и растет. И это замечательно. Но количество информации, которую требуется усвоить, просто зашкаливает и, даже уже работая в этой области, постоянно удивляешься, сколь многое ты еще не знаешь. Скорость появления новых словосочетаний в DS-специальностях тоже крайне высокая, но за многими страшными словосочетаниями может прятаться совершенно простой смысл. Кроме того, часто подход к задаче следующий: сначала навесить на нее некоторый ярлык - например, object detection и копать в этом направлении. И это правильный и эффективный подход. Оказывается, что иногда несколько подходов с разными названиями могут решать одну и ту же задачу. Недавно в работе Центра компетенции больших данных и искусственного интеллекта ЛАНИТ (ЦК ДАТА), мы столкнулись с одной задачей по классификации текстов, на которой мне захотелось такой эффект продемонстрировать.
Подборка о релокейте: страны, в которых хорошо

Мы уже несколько лет выпускаем на Хабре истории о переезде. Некоторые успешные, некоторые не очень (примерно 30% экспатов со временем возвращались).
Сейчас тема стала особенно актуальной. И, может быть парадоксально, но количество вакансий из других стран (тег «Релокейт») у нас в боте тоже выросло в полтора раза. Никакой русофобии и близко не наблюдается, компании понимают, что сейчас уникальный шанс получить мозги, выезжающие из страны.
Если кто-то задумался о том, что делать, — вот личные истории из тех стран, в которые сейчас реально переехать, и в которых относительно просто построить новую жизнь.
Пора релоцироваться
Популярные мифы, советы по поиску работы, переезду и полезные ссылки для тех, кто сейчас ищет работу за рубежом или уже нашел и собирается переехать.
Россия 2022: как не потерять все (или хотя бы попытаться)
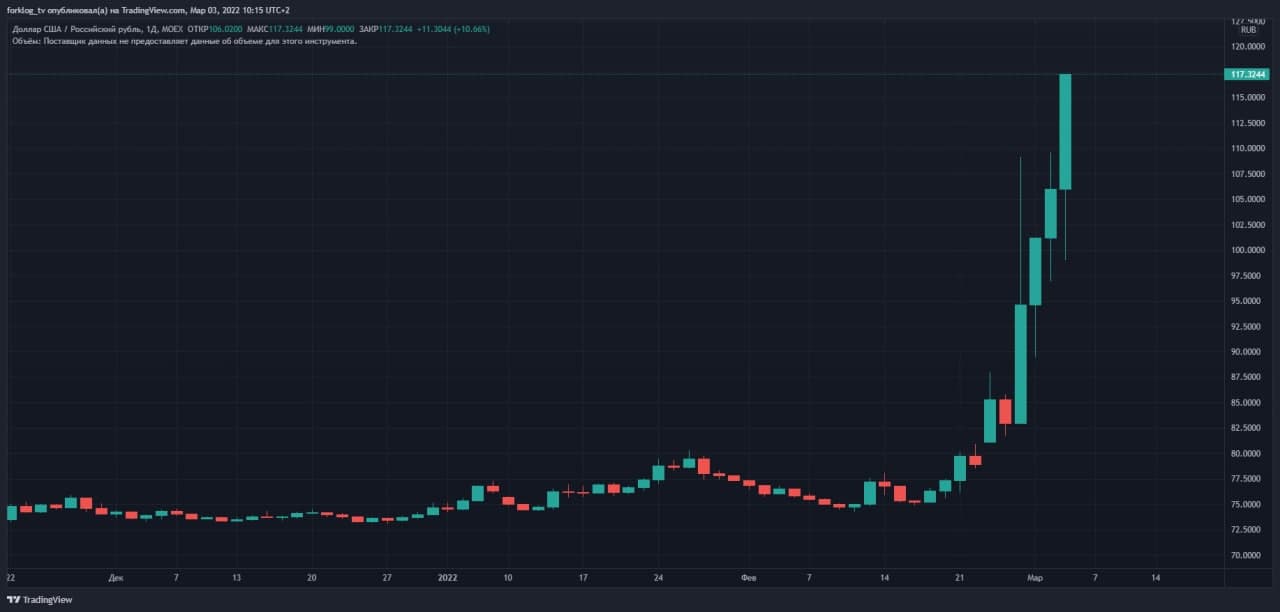
Peace, Хабр!
Честно говоря, я долго думал, как бы потактичнее начать. Но ничего не придумал. Поэтому напишу прямо: я хочу, чтоб моя жена и ребенок ни в чем не нуждались. И у меня была уверенность, что могу им дать все, что потребуется: от любви до игрушечной железной дороги.
Сегодня пошел 8-ой день, как от этой уверенности почти ничего не осталось.
Этот пост не про деньги (хоть он и почти весь про финансы). Этот пост про то, как увеличить свои шансы и шансы своих близких жить в достатке в условиях экономической изоляции и деградации гражданских институтов.
Гайд: работающие способы вывести деньги за рубеж / завести в Россию
В этой статье я постарался систематизировать всю имеющуюся на текущий момент информацию о том, как можно переместить капитал в том или ином виде через российскую границу.
Проблемы современного машинного обучения

Во многих популярных курсах машинного и глубокого обучения вас научат классифицировать собак и кошек, предсказывать цены на недвижимость, покажут еще десятки задач, в которых машинное обучение, вроде как, отлично работает. Но вам расскажут намного меньше (или вообще ничего) о тех случаях, когда ML-модели не работают так, как ожидалось.
Частой проблемой в машинном обучении является неспособность ML-моделей корректно работать на большем разнообразии примеров, чем те, что встречались при обучении. Здесь идет речь не просто о других примерах (например, тестовых), а о других типах примеров. Например, сеть обучалась на изображениях коровы, в которых чаще всего корова был на фоне травы, а при тестировании требуется корректное распознавание коровы на любом фоне. Почему ML-модели часто не справляются с такой задачей и что с этим делать – мы рассмотрим далее. Работа над этой проблемой важна не только для решения практических задач, но и в целом для дальнейшего развития ИИ.
Tfidfvectorizer, BERT, LASER: векторизация данных и кластерный анализ для улучшения рекомендательной системы

Мир онлайн-покупок становится всё привычнее, а значит, и обезличенных данных про каждого пользователя всё больше. Билайн ТВ использует для онлайн-кинотеатра рекомендательную систему на основе данных: она советует пользователю новый триллер, если он уже посмотрел пять похожих фильмов.
Чтобы реализовать такую систему, компания CleverData (группа ЛАНИТ) сформировала эмбеддинги для пользователей Билайн ТВ. Ассоциация больших данных помогла сделать этот кейс возможным.
В этой статье расскажем подробности этой задачи:
Основы Postman для самых маленьких

В этой статье поговорю про основы работы с Postman для начинающих тестировщиков. Сама я столкнулась с этим инструментом как раз на последнем проекте.
Расскажу, как с его помощью создавать простейшие автотесты и уменьшать объем рутины с помощью переменных.
Простые модификации для улучшения табличных нейронных сетей

Simple Modifications to Improve Tabular Neural Networks
Растет интерес к архитектуре нейронных сетей для табличных данных. В последнее время появилось множество табличных моделей глубокого обучения общего назначения, вычислительная мощность которых иногда соперничает с возможностями деревьев решений с градиентным бустингом (GBDT - gradient boosted decision trees). Последние модели черпают вдохновение из различных источников, включая GBDT, машины факторизации и нейронные сети из других областей применения. Предыдущие табличные нейронные сети также используются, но, возможно, недостаточно учтены, особенно для моделей, связанных с конкретными табличными задачами. В данной статье основное внимание уделяется нескольким таким моделям и предлагаются модификации для повышения их производительности. Показано, что при модификации эти модели конкурируют с ведущими табличными моделями общего назначения, включая GBDT.
Введение
В последнее время многие архитектуры нейронных сетей были представлены в качестве табличных решений общего назначения. Некоторые примеры: Tabnet (Арик и Пфистер 2020), TabTransformer (Хуан и др. 2020), NODE (Попов, Морозов и Бабенко 2019), DNF-сеть (Абутбул и др. 2020). Внедрение этих и других моделей демонстрирует растущий интерес к применению глубокого обучения к табличным данным. Это не связано с отсутствием решений, выходящих за пределы возможностей глубокого обучения. Деревья решений с градиентным бустингом (GBDT) являются классом очень хороших моделей общего назначения и фактически часто используются табличными моделями глубокого обучения – как в качестве источника вдохновения, так и в качестве стандарта по производительности.
Методы оптимизации нейронных сетей
В подавляющем большинстве источников информации о нейронных сетях под «а теперь давайте обучим нашу сеть» понимается «скормим целевую функцию оптимизатору» лишь с минимальной настройкой скорости обучения. Иногда говорится, что обновлять веса сети можно не только стохастическим градиентным спуском, но безо всякого объяснения, чем же примечательны другие алгоритмы и что означают загадочные и
в их параметрах. Даже преподаватели на курсах машинного обучения зачастую не заостряют на этом внимание. Я бы хотел исправить недостаток информации в рунете о различных оптимизаторах, которые могут встретиться вам в современных пакетах машинного обучения. Надеюсь, моя статья будет полезна людям, которые хотят углубить своё понимание машинного обучения или даже изобрести что-то своё.

Под катом много картинок, в том числе анимированных gif.
Способы представления аудио в ML

В статье рассмотрены основные формы представления аудио для дальнейшего использования в различных сферах обработки данных.
Работа по ИП или ТК РФ (выбор «IT-шника»)

В этой статье хочу провести анализ особенностей работы в качестве ИП, раскрыть некоторые юридические аспекты, провести сравнение ИП и работы в штате, также затронуть финансовую сторону вопроса (куда же без этого). Я надеюсь, что информация, представленная в статье, окажется полезной, особенно тем, кто сейчас также стоит перед подобным нелегким выбором или только начинает задумываться на эту тему.
Нейродайджест: главное из области машинного обучения за декабрь 2021
Генерация 3D-моделей из текстового описания и видеозаписей, сделанных на обыкновенный смартфон, конкурент DALL-E, ускоренная GAN-инверсия и многое другое в подборке материалов за декабрь, а также небольшие новости о будущем дайджеста.
Обзор архитектуры Swin Transformer
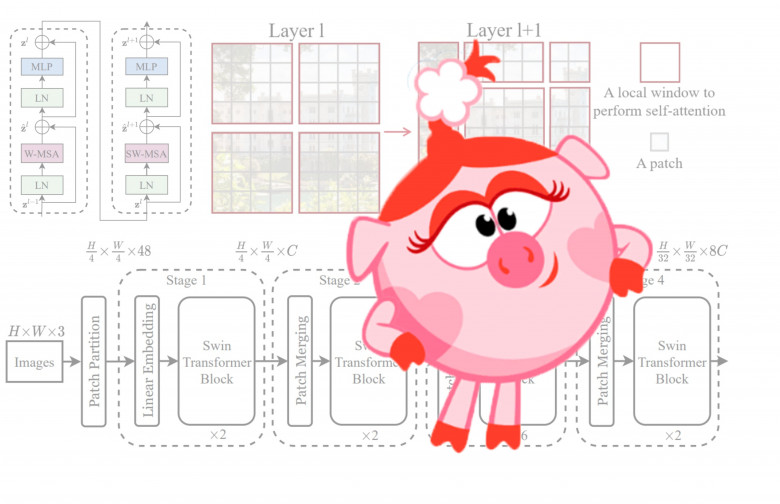
Трансформеры шагают по планете! В статье вспомним/узнаем как работает visual attention, поймём что с ним не так, а главное как его поправить, чтобы получить на выходе best paper ICCV21.
Как оптимизировать проект Data Science с помощью Prefect

Есть ли способ оптимизировать рабочий процесс проекта Data Science всего в несколько строк кода? Да. Это Prefect. Делимся кратким руководством по работе с этим инструментом, пока у нас начинается флагманский курс Data Science.
Как хранить данные в png, не привлекая внимания санитаров

Всё началось с мема, который вы видите выше.
Сначала я посмеялся. А потом задумался: может ли быть так, что скриншот базы равноценен её снэпшоту?
Для этого у нас должно быть такое графическое представление базы, которое 1 к 1 отображает данные и структуру. Если сделать скриншот такого представления, из него можно восстановить базу.
Или... графическое представление и должно быть базой!
ruDALL-E: генерируем изображения по текстовому описанию, или Самый большой вычислительный проект в России

2021 год в машинном обучении ознаменовался мультимодальностью — активно развиваются нейросети, работающие одновременно с изображениями, текстами, речью, музыкой. Правит балом, как обычно, OpenAI, но, несмотря на слово «open» в своём названии, не спешит выкладывать модели в открытый доступ. В начале года компания представила нейросеть DALL-E, генерирующую любые изображения размером 256×256 пикселей по текстовому описанию. В качестве опорного материала для сообщества были доступны статья на arxiv и примеры в блоге.
С момента выхода DALL-E к проблеме активно подключились китайские исследователи: открытый код нейросети CogView позволяет решить ту же проблему — получать изображения из текстов. Но что в России? Разобрать, понять, обучить — уже, можно сказать, наш инженерный девиз. Мы нырнули с головой в новый проект и сегодня рассказываем, как создали с нуля полный пайплайн для генерации изображений по описаниям на русском языке.
В проекте активно участвовали команды SberAI, SberDevices, Самарского университета, AIRI и SberCloud.
Мы обучили две версии модели разного размера и дали им имена великих российских абстракционистов – Василия Кандинского и Казимира Малевича:
1. ruDALL-E Kandinsky (XXL) с 12 миллиардами параметров;
2. ruDALL-E Malevich (XL), содержащая 1,3 миллиарда параметров.
Некоторые версии наших моделей доступны в open source уже сейчас:
1. ruDALL-E Malevich (XL) [GitHub, HuggingFace]
2. Sber VQ-GAN [GitHub, HuggingFace]
3. ruCLIP Small [GitHub, HuggingFace]
4. Super Resolution (Real ESRGAN) [GitHub, HuggingFace]
Две последние модели встроены в пайплайн генерации изображений по тексту (об этом расскажем ниже).
Версии моделей ruDALL-E Malevich (XL), ruDALL-E Kandinsky (XXL), ruCLIP Small, ruCLIP Large, Super Resolution (Real ESRGAN) также скоро будут доступны в DataHub.
Обучение нейросети ruDALL-E на кластере Christofari стало самой большой вычислительной задачей в России:
1. Модель ruDALL-E Kandinsky (XXL) обучалась 37 дней на 512 GPU TESLA V100, а затем ещё 11 дней на 128 GPU TESLA V100 — всего 20 352 GPU-дней;
2. Модель ruDALL-E Malevich (XL) обучалась 8 дней на 128 GPU TESLA V100, а затем еще 15 дней на 192 GPU TESLA V100 – всего 3 904 GPU-дня.
Таким образом, суммарно обучение обеих моделей заняло 24 256 GPU-дней.
Разберём возможности наших генеративных моделей.