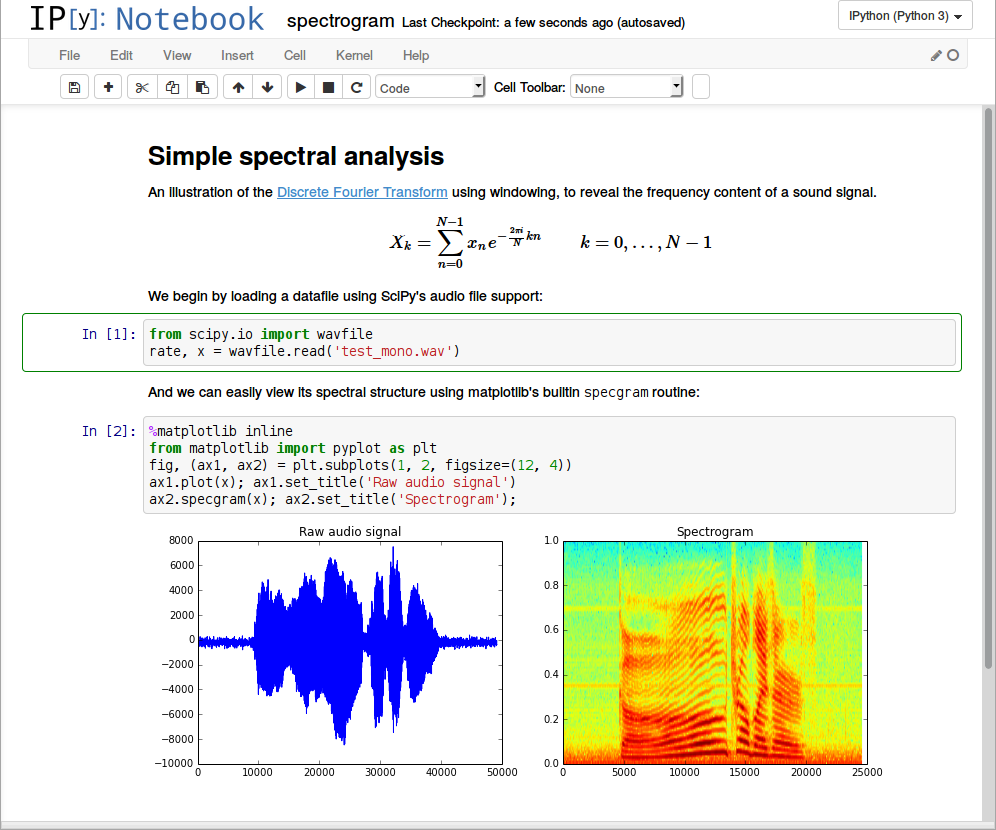
Как мы разработали технологию обнаружения устройств поблизости
7 min

Эта история началась с функции “Рядом” в одном из наших мобильных приложений. Мы хотели, чтобы пользователи могли быстро создать групповой чат или добавить находящихся рядом пользователей в друзья. Мы попробовали решить эту задачу при помощи геолокации, Bluetooth, Wi-Fi и ультразвука, но у каждого из способов мы обнаружили критичные в нашем случае недостатки.
В итоге мы придумали новый способ. Он основан на поиске совпадения окружающего шума: если устройства слышат одно и то же, то, скорее всего, они находятся рядом.
В статье мы расскажем о принципе его работы, а также рассмотрим достоинства и недостатки других распространенных способов обнаружения устройств.


 abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.
abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.







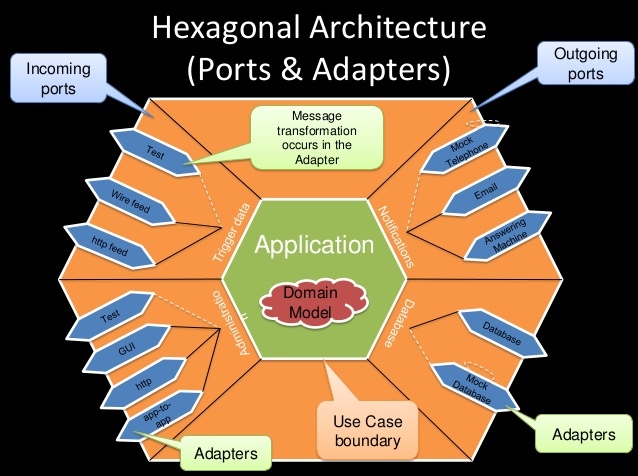
 Здравствуйте, коллеги. В конце 1960-ых годов прошлого века
Здравствуйте, коллеги. В конце 1960-ых годов прошлого века