Фабрис Беллар: портрет сверхпродуктивного программиста
3 min
Как в компьютерной индустрии есть обычные ПК и суперкомпьютеры, также и среди разработчиков выделяются эдакие гиганты, обладающие сверхсилой. Как ещё можно назвать человека, чей список проектов выглядит так:
1989: LZEXE
1996: Harissa
1997: Публикация формулы Беллара для вычисления разрядов числа Пи
1999: Linmodem
2000: Вычисление самого большого известного простого числа (исходный код всего 438 байт)
2000: FFmpeg
2001: Компилятор TCC (Tiny C Compiler или TinyCC)
2002: TinyGL
2002: QEmacs
2003: QEMU
2004: Загрузчик TinyCC
2005: Передатчик сигнала в формате DVB-T с компьютера на телевизор
2009: Мировой рекорд по вычислению числа Пи
2011: Эмулятор компьютера с Linux на JavaScript
Каждая из этих программ могла бы стать венцом карьеры для любого разработчика, но Фабрис Беллар продолжает работать.
1989: LZEXE
1996: Harissa
1997: Публикация формулы Беллара для вычисления разрядов числа Пи
1999: Linmodem
2000: Вычисление самого большого известного простого числа (исходный код всего 438 байт)
2000: FFmpeg
2001: Компилятор TCC (Tiny C Compiler или TinyCC)
2002: TinyGL
2002: QEmacs
2003: QEMU
2004: Загрузчик TinyCC
2005: Передатчик сигнала в формате DVB-T с компьютера на телевизор
2009: Мировой рекорд по вычислению числа Пи
2011: Эмулятор компьютера с Linux на JavaScript
Каждая из этих программ могла бы стать венцом карьеры для любого разработчика, но Фабрис Беллар продолжает работать.



 В этой статье я расскажу о начале своей работы над совершенно безбашенной задачей: конечная цель в том, чтобы получить рабочую микросхему по «толстым» нормам (5-10µm) дома. Это не первое апреля и я не сумасшедший, это просто моё хобби.
В этой статье я расскажу о начале своей работы над совершенно безбашенной задачей: конечная цель в том, чтобы получить рабочую микросхему по «толстым» нормам (5-10µm) дома. Это не первое апреля и я не сумасшедший, это просто моё хобби.
 Дорогие мои, любимые, сохабровцы! Должен признаться вам, что я, на правах религиозного фанатика, являюсь совершенно счастливым человеком, но последних лет 16, из своих 32, наблюдаю вокруг все усугубляющуюся картину борьбы общества с абсурдностью бытия. Дело в том, что многие из моих знакомых работают в крупных компаниях, где их безжалостно гнобит офисная сансара, а у меня, уж так сложилось, никогда не было жесткого графика и довлеющей корпоративной машины за спиной, за что я денно и нощно возношу хвалу Аллаху. Находясь на значительном удалении от этих проблем и будучи в них эмоционально не вовлеченным, занимаясь наукой в свое удовольствие в НИИ Системных технологий (а на жизнь зарабатывая собственным ИТ-бизнесом), при помощи чудодейственного системного анализа я постараюсь обобщить тут все, что знаю по теме.
Дорогие мои, любимые, сохабровцы! Должен признаться вам, что я, на правах религиозного фанатика, являюсь совершенно счастливым человеком, но последних лет 16, из своих 32, наблюдаю вокруг все усугубляющуюся картину борьбы общества с абсурдностью бытия. Дело в том, что многие из моих знакомых работают в крупных компаниях, где их безжалостно гнобит офисная сансара, а у меня, уж так сложилось, никогда не было жесткого графика и довлеющей корпоративной машины за спиной, за что я денно и нощно возношу хвалу Аллаху. Находясь на значительном удалении от этих проблем и будучи в них эмоционально не вовлеченным, занимаясь наукой в свое удовольствие в НИИ Системных технологий (а на жизнь зарабатывая собственным ИТ-бизнесом), при помощи чудодейственного системного анализа я постараюсь обобщить тут все, что знаю по теме.
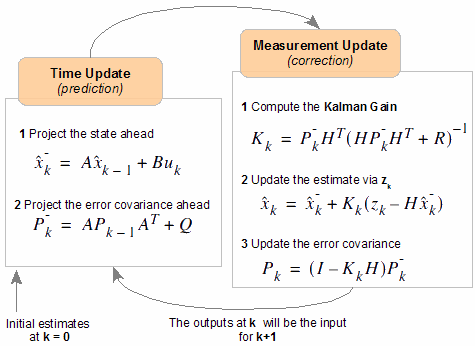 Недавно прочитал пост из «Дополненной реальности», в котором упоминается Фильтр Калмана в сравнении с более простым «альфа-бета» фильтром. Давно собирался сочинить нечто вроде сниппета по составлению ФК, и вот думаю самое время. В статье я вам расскажу как на практике можно составить расширенный ФК не особо утруждая себя высоконаучными размышлениями и глубокими теоретическими изысканиями.
Недавно прочитал пост из «Дополненной реальности», в котором упоминается Фильтр Калмана в сравнении с более простым «альфа-бета» фильтром. Давно собирался сочинить нечто вроде сниппета по составлению ФК, и вот думаю самое время. В статье я вам расскажу как на практике можно составить расширенный ФК не особо утруждая себя высоконаучными размышлениями и глубокими теоретическими изысканиями.