Привет, Хабр! Меня зовут Алан Савушкин (@naive_bayes), я — дата-сайентист в команде Data Science & Big Data «Лаборатории Касперского», и мы отвечаем в том числе за фильтрацию нерелевантных алертов при телеметрии киберугроз в проекте Kaspersky Managed Detection and Response (MDR).
В данной статье хочу с вами поделиться, как мы решали задачу построения оценки TPR (True Positive Rate) в условиях неполной разметки данных. Может возникнуть вопрос: а что там оценивать? TPR по своей сути всего лишь доля, а построить доверительный интервал на долю легче простого.
Спорить не буду, но добавлю, что из статьи вы узнаете:
— Что даже в использовании такого интервала есть свои условия.
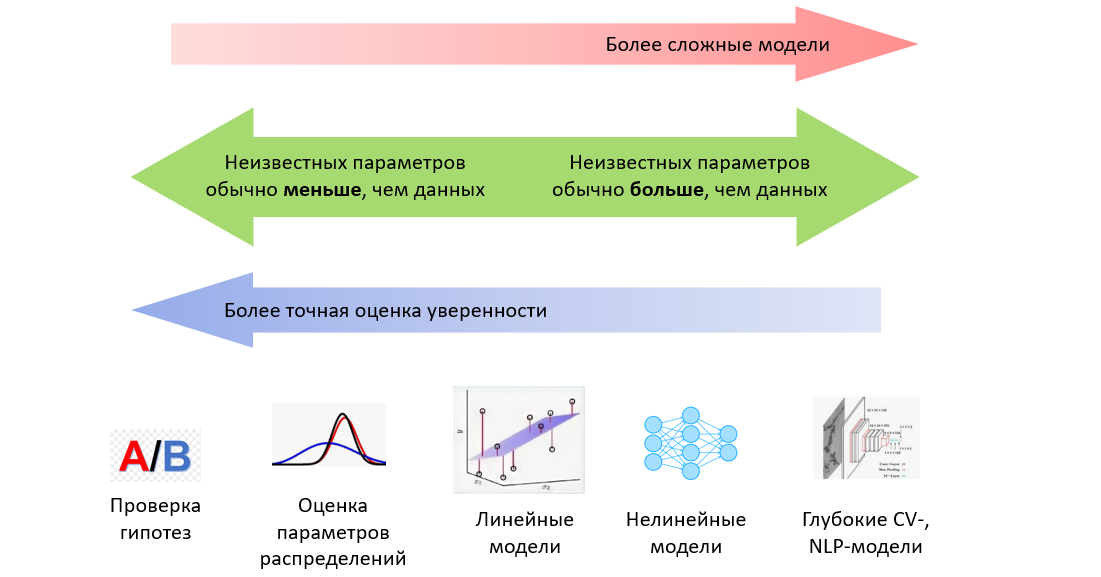
— Как на основе серии проверки гипотез получить доверительный интервал, используя под капотом гипергеометрическое распределение. А можно ли использовать биномиальное? Спойлер: можно, но тогда важно понимать, на какой вопрос вы отвечаете, пользуясь такой оценкой. Здесь мы рассмотрим задачу с частотной точки зрения.
— Что будет, если скрестить биномиальное распределение с бета‑распределением, и как этот гибрид используется в качестве сопряженного априорного распределения для гипергеометрического распределения. А здесь мы рассмотрим задачу с байесовской точки зрения.
— И, собственно, в чем прикол этой неполной разметки данных, и как мы докатились до всего перечисленного выше.
Тизер получился обширным, и если вам стало интересно — что ж, тогда давайте разбираться.










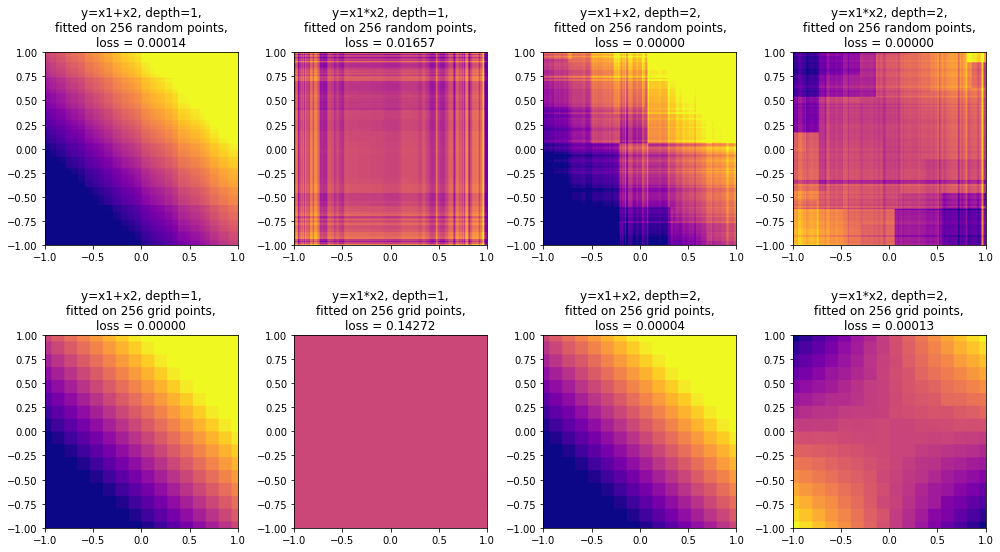
 . Поговорим также о выводах, которые можно из этого сделать.
. Поговорим также о выводах, которые можно из этого сделать.


