Читать дальше →

ish @ish
User
 Эта статья — How To, которое поможет вам легко обеспечить миграцию между версиями БД ваших PHP приложений с помощью
Эта статья — How To, которое поможет вам легко обеспечить миграцию между версиями БД ваших PHP приложений с помощью Несколько удобных инструментов для тестирования сайта
3 min
Представляю вашему вниманию обзор нескольких полезных инструментов для всестороннего тестирования сайтов.
Memcached — стратегия кеширования
6 min
Хочу поприветствовать хабросообщество. Из приятных впечатлении при регистрации на Хабре — так это атмосфера сказочности, которая бывает только в старых добрых сказках из советского Кинофильма.
Итак, слезы умиления прошли, приступаем. Ниже топик, который привел к инвайту на Хабр.
Memcached применяется для кеширования данных. Это делается для того, чтобы избежать лишних обращений к базе данных, т.е. в Memcached сохраняют результаты запросов. Это ускоряет работу сайта и уменьшают время выдачи страниц.
Кеш кроме преимуществ имеет свои недостатки. Одна из проблем кеша — это его актуальность. В режиме работы «только чтение» трудностей не возникает. Если же мы имеем дело с данными, которые изменяются, или изменяются часто, то эффективность кеширования резко падает.
Итак, слезы умиления прошли, приступаем. Ниже топик, который привел к инвайту на Хабр.
Memcached применяется для кеширования данных. Это делается для того, чтобы избежать лишних обращений к базе данных, т.е. в Memcached сохраняют результаты запросов. Это ускоряет работу сайта и уменьшают время выдачи страниц.
Кеш кроме преимуществ имеет свои недостатки. Одна из проблем кеша — это его актуальность. В режиме работы «только чтение» трудностей не возникает. Если же мы имеем дело с данными, которые изменяются, или изменяются часто, то эффективность кеширования резко падает.
Сделайте свой сайт более доступным для поиска
5 min
Translation
Джон Мюллер, Специалист по анализу веб-трендов (Google Цюрих)
Цель — доступность и полезность информации
Миссия Google заключается в организации мировой информации, обеспечении её доступности и пользы для всех. Залогом успеха реализации этой миссии является непрерывное сканирование интернета в поисках свежего содержания и добавлениe его в наш индекс. Мы регулярно сканируем миллиарды страниц, а знаем о существовании ещё большего числа документов: мы индексируем веб-страницы, форумы, изображения, новости, видео, книги и многое другое. Но иногда пользователи хотят найти ещё больше. Зачастую это информация, которая опубликована онлайн, но по тем или иным причинам недоступна для наших сканеров. Если у сканеров нет доступа к документам, поисковой системе будет сложно их полностью проиндексировать и предоставить пользователям.
Проиндексированы ли ваши веб-страницы?
Проверить, насколько проиндексировано содержание вашего сайта, легко: для этого произведите поиск URL-адреса вашего домена с оператором «site:». Например, чтобы проверить какая часть Групп Google проиндексирована нашим поисковиком, нужно сделать запрос [site:groups.google.com] (в тексте мы обычно заключаем поисковые запросы в квадратные скобки, но этого не делать непосредственно в строке поискового запроса; также обратите внимание, что в запросе после оператора «site:» отсутствует пробел).

В данном примере видно, что проиндексировано большое количество страниц, а первым результатом является главная страница Групп Google. Это хорошо — в наличии множество информации, многие сообщения уже проиндексированы и доступны пользователям.
Если ваш сайт плохо индексируется, то в окне результатов поиска вы либо обнаружите отсутствие ссылок на содержание вашего сайта, либо таких ссылок будет мало. Эта проблема проиллюстрирована в следующем примере. В данном случае, домен example.com не сканируется нашим поисковым роботом. Если вы сделаете запрос [site:example.com], в результатах поиска вы увидите, что, в отличие от Групп Google, страницы сайта example.com не индексируются:

Мой сайт выглядит похоже на скриншот вверху! Что делать, чтобы исправить ситуацию?
Если ваш сайт индексируется так же, как показано в предыдущем примере, или совсем не индексируется, не стоит впадать в панику. В интернете ничто не постоянно. В большинстве случаев можно выяснить и устранить эту проблему достаточно быстро. Вот несколько вещей, которые стоит проверить:
В некоторых случаях веб-мастера блокируют доступ всем поисковым роботам, чтобы избежать чрезмерной нагрузки на веб-сервер, которая может произойти при интенсивном сканировании сайта. В такой ситуации, вместо того, чтобы запрещать сканирование всего сайта, будет полезно идентифицировать отдельные страницы, которые являются причиной проблемы, и блокировать только их. Также стоит задать частоту сканирования в настройках инструментов для веб-мастеров Google, если вы считаете, что это поможет уменьшить нагрузку на сервер.
Содержимое файла robots.txt определённого сайта (также вашего) можно посмотреть в любом браузере. Например, можно посмотреть содержимое файла robots.txt сайта YouТube.com.
В консоли инструментов для веб-мастеров Google есть программа для анализа файла robots.txt. Там же можно создать файл robots.txt для вашего сайта, если у вас его нет (хотя наличие на сайте файла robots.txt необязательно).
Следующие строки в файле robots.txt запрещают доступ всем поисковым роботам ко всему содержимому сайта ("/" — обозначает корневой уровень файлового дерева сайта):
User-agent: *
Disallow: /
Следующие строки в robots.txt разрешают доступ к содержимому сайта всем роботам:
User-agent: *
Disallow:
Заметьте, что после директивы «Disallow:» ничего не написано. Отсутствие у вашего сайта файла robots.txt имеет такой же эффект.
Комментарии в файлах robots.txt можно добавлять используя символ # в начале строки, например так:
# это комментарий
Информацию об ошибках сканирования (например URL, запрещенные файлом robots.txt) вы можете найти в консоли инструментов для веб-мастеров Google. Чтобы иметь доступ к этой информации, убедитесь, что ваш сайт добавлен и подтвержден.
Часто причиной этого является то, что настройка, включенная по умолчанию, не была выключена в программном обеспечении сайта. Иногда названия таких настроек могут быть неясны или слабо связаны с этим метатегом. Например, название настройки может быть «видимость сайта» или «разрешить поисковым роботам искать на вашем сайте».
Если вы проверили свой сайт при помощи вышеупомянутым методов, и вам кажется, что ваш сайт уже давно должен был быть отсканирован и проиндексирован, возможно, вам будет полезно посмотреть в архивe форума, не сталкивались ли с похожей проблемой другие веб-мастера. Вы также можете задать свой вопрос на форуме. После того как вы приняли необходимые меры, сканирование и индексирование вашего сайта в большинстве случаев — это вопрос времени.
Спасибо, что у вас нашлось время и терпение, чтобы проверить свой сайт. Мы надеемся, это поможет сделать ваш сайт эффективным для поискового сканирования и улучшить его видимость для ваших пользователей!

Цель — доступность и полезность информации
Миссия Google заключается в организации мировой информации, обеспечении её доступности и пользы для всех. Залогом успеха реализации этой миссии является непрерывное сканирование интернета в поисках свежего содержания и добавлениe его в наш индекс. Мы регулярно сканируем миллиарды страниц, а знаем о существовании ещё большего числа документов: мы индексируем веб-страницы, форумы, изображения, новости, видео, книги и многое другое. Но иногда пользователи хотят найти ещё больше. Зачастую это информация, которая опубликована онлайн, но по тем или иным причинам недоступна для наших сканеров. Если у сканеров нет доступа к документам, поисковой системе будет сложно их полностью проиндексировать и предоставить пользователям.
Проиндексированы ли ваши веб-страницы?
Проверить, насколько проиндексировано содержание вашего сайта, легко: для этого произведите поиск URL-адреса вашего домена с оператором «site:». Например, чтобы проверить какая часть Групп Google проиндексирована нашим поисковиком, нужно сделать запрос [site:groups.google.com] (в тексте мы обычно заключаем поисковые запросы в квадратные скобки, но этого не делать непосредственно в строке поискового запроса; также обратите внимание, что в запросе после оператора «site:» отсутствует пробел).
В данном примере видно, что проиндексировано большое количество страниц, а первым результатом является главная страница Групп Google. Это хорошо — в наличии множество информации, многие сообщения уже проиндексированы и доступны пользователям.
Если ваш сайт плохо индексируется, то в окне результатов поиска вы либо обнаружите отсутствие ссылок на содержание вашего сайта, либо таких ссылок будет мало. Эта проблема проиллюстрирована в следующем примере. В данном случае, домен example.com не сканируется нашим поисковым роботом. Если вы сделаете запрос [site:example.com], в результатах поиска вы увидите, что, в отличие от Групп Google, страницы сайта example.com не индексируются:
Мой сайт выглядит похоже на скриншот вверху! Что делать, чтобы исправить ситуацию?
Если ваш сайт индексируется так же, как показано в предыдущем примере, или совсем не индексируется, не стоит впадать в панику. В интернете ничто не постоянно. В большинстве случаев можно выяснить и устранить эту проблему достаточно быстро. Вот несколько вещей, которые стоит проверить:
- Является ли ваш сайт новым?
- Открыт ли ваш сайт для сканирования поисковыми роботами?
В некоторых случаях веб-мастера блокируют доступ всем поисковым роботам, чтобы избежать чрезмерной нагрузки на веб-сервер, которая может произойти при интенсивном сканировании сайта. В такой ситуации, вместо того, чтобы запрещать сканирование всего сайта, будет полезно идентифицировать отдельные страницы, которые являются причиной проблемы, и блокировать только их. Также стоит задать частоту сканирования в настройках инструментов для веб-мастеров Google, если вы считаете, что это поможет уменьшить нагрузку на сервер.
Содержимое файла robots.txt определённого сайта (также вашего) можно посмотреть в любом браузере. Например, можно посмотреть содержимое файла robots.txt сайта YouТube.com.
В консоли инструментов для веб-мастеров Google есть программа для анализа файла robots.txt. Там же можно создать файл robots.txt для вашего сайта, если у вас его нет (хотя наличие на сайте файла robots.txt необязательно).
Следующие строки в файле robots.txt запрещают доступ всем поисковым роботам ко всему содержимому сайта ("/" — обозначает корневой уровень файлового дерева сайта):
User-agent: *
Disallow: /
Следующие строки в robots.txt разрешают доступ к содержимому сайта всем роботам:
User-agent: *
Disallow:
Заметьте, что после директивы «Disallow:» ничего не написано. Отсутствие у вашего сайта файла robots.txt имеет такой же эффект.
Комментарии в файлах robots.txt можно добавлять используя символ # в начале строки, например так:
# это комментарий
Информацию об ошибках сканирования (например URL, запрещенные файлом robots.txt) вы можете найти в консоли инструментов для веб-мастеров Google. Чтобы иметь доступ к этой информации, убедитесь, что ваш сайт добавлен и подтвержден.
- Не запрещает ли ваш сайт индексирование содержания?
Часто причиной этого является то, что настройка, включенная по умолчанию, не была выключена в программном обеспечении сайта. Иногда названия таких настроек могут быть неясны или слабо связаны с этим метатегом. Например, название настройки может быть «видимость сайта» или «разрешить поисковым роботам искать на вашем сайте».
- Вы уверены, что нет других технических проблем, блокирующих поисковые системы?
- Соответствует ли ваш сайт рекомендациям по обеспечению качества Google?
Если вы проверили свой сайт при помощи вышеупомянутым методов, и вам кажется, что ваш сайт уже давно должен был быть отсканирован и проиндексирован, возможно, вам будет полезно посмотреть в архивe форума, не сталкивались ли с похожей проблемой другие веб-мастера. Вы также можете задать свой вопрос на форуме. После того как вы приняли необходимые меры, сканирование и индексирование вашего сайта в большинстве случаев — это вопрос времени.
Спасибо, что у вас нашлось время и терпение, чтобы проверить свой сайт. Мы надеемся, это поможет сделать ваш сайт эффективным для поискового сканирования и улучшить его видимость для ваших пользователей!
JuffEd 0.7.528 или Что версия 0.8.0 нам готовит
4 min
Добрый день.
После довольно удачного (как мне показалось :)) анонса на Хабре редактора JuffEd (см. ссылку в конце статьи) пришла пора отчитаться о проделанной работе. В первую очередь хочу выразить огромную благодарность всем, кто принял участие в тестировании версии 0.6.0, кто оставлял пожелания и сообщения о багах.
Версия 0.8.0 скоро увидит свет, а пока что (для самых смелых и нетерпеливых) представляю превью-версию 0.7.528, в которой реализовано довольно много новых фич, в том числе и тех, о которых просили хабраюзеры в комментариях к анонсу версии 0.6.0. Были учтены многие пожелания, но пока что не все, поэтому если вам чего-то ну очень хочется — не стесняйтесь настоять на этом :)
Итак, что же нового в этой версии?
После довольно удачного (как мне показалось :)) анонса на Хабре редактора JuffEd (см. ссылку в конце статьи) пришла пора отчитаться о проделанной работе. В первую очередь хочу выразить огромную благодарность всем, кто принял участие в тестировании версии 0.6.0, кто оставлял пожелания и сообщения о багах.
Версия 0.8.0 скоро увидит свет, а пока что (для самых смелых и нетерпеливых) представляю превью-версию 0.7.528, в которой реализовано довольно много новых фич, в том числе и тех, о которых просили хабраюзеры в комментариях к анонсу версии 0.6.0. Были учтены многие пожелания, но пока что не все, поэтому если вам чего-то ну очень хочется — не стесняйтесь настоять на этом :)
Итак, что же нового в этой версии?
Как вовремя узнать, что ваш сервер не работает?
3 min
Случается, что сайты перестают работать. Причины могут быть самые разные: в датацентре «упал» канал, сервер вырубился, кто-то что-то намудрил с базой или файлами на сервере, сисадмин неудачно обновил ПО или переносил аккаунты. Или кое-кто забыл оплатить хостинг.
В большинстве случаев такая ситуация нежелательна, а устранить ее надо как можно скорее. Для этого нужно как можно скорее узнать о случившемся. Но как? Для себя и для наших клиентов мы используем сервисы мониторинга сайтов. О них я сегодня и расскажу.
В большинстве случаев такая ситуация нежелательна, а устранить ее надо как можно скорее. Для этого нужно как можно скорее узнать о случившемся. Но как? Для себя и для наших клиентов мы используем сервисы мониторинга сайтов. О них я сегодня и расскажу.
Реализация отправки sms-уведомлений
3 min
В виду достаточно большого парка серверов/свитчей/модемов и иного активного оборудования в конторе, была установленная система мониторинга zabbix и успешно использовалась продолжительное время. Zabbix имеет замечательную возможность отправки уведомлений о возникших проблемах.
Для этого был написан скрипт отправки sms сообщений через шлюз email-to-sms оператора связи, ограничение по количеству смс с одного адреса в сутки было обойдено путем ротации исходящих адресов, работало более или мение сносно, но в последнее время смс сообщения через данный шлюз начали доходить с задержкой порядка 10-15 минут, что уже не очень нравилось.
Итак, было решено организовать отправку уведомлений через собственный GSM-терминал, порывшись в прайсах поставщиков и не обнаружив там подходящих по цене и характеристикам GSM модемов весьма огорчился.
И тут вспомнилось что дома валяется старый Siemens CX65 да еще и data-кабель к нему, после подключения телефона и курения доков по отправке sms сообщений пришел к не очень радостному выводу, оказывается siemens не поддерживает отправку sms в текстовом режиме, команда AT+CMGF=1 возвращает error.
Отправка сообщений в данных аппаратах возможна только в режиме PDU, ради спортивного интереса и для размятия мозгов было решено реализовать эту систему, был написан скрипт для перекодировки в PDU формат сообщений и отправки через телефон.
Для этого был написан скрипт отправки sms сообщений через шлюз email-to-sms оператора связи, ограничение по количеству смс с одного адреса в сутки было обойдено путем ротации исходящих адресов, работало более или мение сносно, но в последнее время смс сообщения через данный шлюз начали доходить с задержкой порядка 10-15 минут, что уже не очень нравилось.
Итак, было решено организовать отправку уведомлений через собственный GSM-терминал, порывшись в прайсах поставщиков и не обнаружив там подходящих по цене и характеристикам GSM модемов весьма огорчился.
И тут вспомнилось что дома валяется старый Siemens CX65 да еще и data-кабель к нему, после подключения телефона и курения доков по отправке sms сообщений пришел к не очень радостному выводу, оказывается siemens не поддерживает отправку sms в текстовом режиме, команда AT+CMGF=1 возвращает error.
Отправка сообщений в данных аппаратах возможна только в режиме PDU, ради спортивного интереса и для размятия мозгов было решено реализовать эту систему, был написан скрипт для перекодировки в PDU формат сообщений и отправки через телефон.
Автоматическая фотожабилка — мы смогли это сделать)
1 min
Все любят фотожабы, но отлично готовить их умеют единицы, умельцы Photoshop.
На смену «деревенской лошадке» пришла автоматическая фотожабилка с молодежного портала tinza.ru – специальный сервис Фотоприколы.

Сайт сделан для школьников и тинов, и задача стояла сделать сервис максимально простым и понятным, но мы решили, что это может быть прикольно не только детям.
Секрет сервиса прост – загружается фотка в фас, сервер автоматически распознает лицо и делает цветокоррекцию, флеш отображает результат и позволяет сделать легкий тюнинг.
Будем рады услышать ваши замечания и предложения по автофотожабилке – оставляйте их на нашем проекте обратной связи на tinza.reformal.ru
P.S. господа минусующие — это ведь шутка юмора, не будьте такими серьёзными)
На смену «деревенской лошадке» пришла автоматическая фотожабилка с молодежного портала tinza.ru – специальный сервис Фотоприколы.
Сайт сделан для школьников и тинов, и задача стояла сделать сервис максимально простым и понятным, но мы решили, что это может быть прикольно не только детям.
Секрет сервиса прост – загружается фотка в фас, сервер автоматически распознает лицо и делает цветокоррекцию, флеш отображает результат и позволяет сделать легкий тюнинг.
Будем рады услышать ваши замечания и предложения по автофотожабилке – оставляйте их на нашем проекте обратной связи на tinza.reformal.ru
P.S. господа минусующие — это ведь шутка юмора, не будьте такими серьёзными)
Regexp — это «язык программирования». Основы
4 min
Несколько лет назад я думал, что regexp осуществляет линейный поиск по тексту, но какое моё удивление было, когда я понял, что это не так. Тогда я убедился на собственном опыте, что от простой смены местами а и b в схеме (...a...)|(...b...) поменялся полностью результат.
Поэтому сейчас я расскажу, как на самом деле работает regexp.
Поняв эти простые принципы и как оно работает, вы сможете писать любые запросы.
Для примера, я разберу сложную при первом приближении, но на самом деле простейшую задачу – выявление всех строк в кавычках.
Поэтому сейчас я расскажу, как на самом деле работает regexp.
Поняв эти простые принципы и как оно работает, вы сможете писать любые запросы.
Для примера, я разберу сложную при первом приближении, но на самом деле простейшую задачу – выявление всех строк в кавычках.
Многоуровневое дерево с маркерами (только HTML, CSS, без Javascript)
5 min
 До того как заняться верской гитарных аккордов (статьи 1,2,3) я столкнулся с необходимостью сделать человеку на сайте меню-дерево. Рисовать не хотелось вообще, поэтому я взял старый добрый HTML с CSS и начал делать это дерево, начал с простого одноуровневого, а позже сделал многоуровневое с маркерами, которое и представлю.
До того как заняться верской гитарных аккордов (статьи 1,2,3) я столкнулся с необходимостью сделать человеку на сайте меню-дерево. Рисовать не хотелось вообще, поэтому я взял старый добрый HTML с CSS и начал делать это дерево, начал с простого одноуровневого, а позже сделал многоуровневое с маркерами, которое и представлю.Позже это дерево дало мне плоды в виде habrahabr.ru/blogs/css/53792
Статья по мотивам моего выступления на PHPConf. Общий обзор Flex-а и связки PHP&Flex
17 min
Статья будет полезна тем, кто хочеть познакомиться с Flex и его интеграцией с PHP, оценить плюсы и минусы использование этого решения в продакшен. Хочу заметить выступление почти двух годичной давности, однако многое (практически все=) до сих пор актуально.
PHP&Flex, «новая» альтернатива для создания Rich Internet Applications
PHP&Flex, «новая» альтернатива для создания Rich Internet Applications
Firebug: Part 4 — profiling
2 min
Как хороший код поможет избежать отладки в дебаггере, так он же поможет вам никогда не применять навыки, полученные в этой статье.
Если на вашем сайте у вас «умирает» браузер от перегрузки javascript'ом, то вам просто необходимо это прочитать(и применить тоже).
Весь цикл: Console, Commands, Debugging ,Profiling
Если на вашем сайте у вас «умирает» браузер от перегрузки javascript'ом, то вам просто необходимо это прочитать(и применить тоже).
Весь цикл: Console, Commands, Debugging ,Profiling
Firebug: Part 2 — commands
2 min
Это продолжение серии статей про Firebug.
Весь цикл: Console, Commands, Debugging ,Profiling
Firebug имеет приятную особенность — собственные функции.
Некоторые из них вам уже встречались, например в Prototype.
И чтобы вы не сомневались в том, что все честно, то мы продолжим мучать домашнюю страничку Firebug, т.к. на ней нет подключенных js файлов.
Весь цикл: Console, Commands, Debugging ,Profiling
Firebug имеет приятную особенность — собственные функции.
Некоторые из них вам уже встречались, например в Prototype.
И чтобы вы не сомневались в том, что все честно, то мы продолжим мучать домашнюю страничку Firebug, т.к. на ней нет подключенных js файлов.
13 плагинов для того, чтобы сделать Gedit более удобным редактором
4 min
Translation
Давайте уделим немного внимания старому доброму текстовому редактору Gedit. Он является дефолтным текстовым редактором для большинства Linux-дистрибутивов использующих Gnome в качестве оконного менеджера. Как выяснилось, и как мы в дальнейшем убедимся, Gedit поддерживает плагины, в числе которых есть много полезных и интересных.
Gentoo+drbd+ocfs2
4 min
Введение
Поставили передо мной как-то задачу… говорят один сервер это хорошо… но учитываю рост посетителей, неплохо бы было повысить производительность отдачи и для этой цели будет приобретен еще 1 сервер…
еще один сервер это хорошо, подумал я… только что с ним делать ??
Поговорив с програмистом и примерно поняв чего он хочет…
А именно одновременную отдачу контента, и что-то типа nfs или шары…
но тогда был бы оверхед ибо данные гонялись по сети и нагружен был бы диск одного сервера, посему надо было чтобы данные одновременно хранились на обоих серверах и реплицировались друг на друга…
поискав в гугле что-то на эту тему нашел информацию по кластерным фс, и для меня подходили gfs2 и позднее обнаруженная ocfs2, но была проблема в том что обычно использовалось выделенное файловое хранилище и его уже монтировали ноды… что было неприемлимо для меня, и тогда позадавав вопросы народу в конференции (gentoo@conference.gentoo.ru благо там были люди работающие с кластерами и прочими веселыми вещами) я вышел на drbd
Включение сглаживания шрифтов в wine
1 min
Как многим из вас уже известно, начиная с версии 1.1.12 wine поддерживает сглаживание шрифтов, включая субпиксельное. Однако по умолчанию это сглаживание выключено. Для его включения нужно пошаманить с реестром в wine. Но есть способ проще:
Я написал небольшой скрипт (английская версия), с помощью которого можно включить/выключить сглаживание, при этом выбрать какой именно режим сглаживания вам нужен:

Быстро загрузить и запусть его можно так:
Я написал небольшой скрипт (английская версия), с помощью которого можно включить/выключить сглаживание, при этом выбрать какой именно режим сглаживания вам нужен:
Быстро загрузить и запусть его можно так:
Скрипт также вполне корректно поддерживает указание WINEPREFIX.wget http://files.polosatus.ru/winefontssmoothing.sh bash winefontssmoothing.sh
Subversion: cлияние переименований файлов
3 min
— Зачем ты, Белка, летишь за мной, Кабаном?
— Не знаю, Кабан! Приказ Хорька. Как понял? Приём.
— Ни хера не понял! Какого Хорька, Белка? Я Кабан. Кто такой Хорёк? Кто это? Приём.
— Кабан, ты дятел! Как понял? Приём.
— Понял тебя, Белка. Я — Дятел. Повторяю вопрос про хорька. Кто это?
— Кабан, сука, ты всех заманал, лети вперёд молча! Конец связи.
Виктор Шендерович
Как известно, Subversion не умеет отслеживать переименования файлов. Согласно документации, команда
svn move равносильна svn copy с последующим svn delete. Такое поведение вызывает большие проблемы при слиянии веток. Рассмотрим способы их решения.Clear или overflow:hidden — очистка всего потока или создание контекста форматирования?
2 min
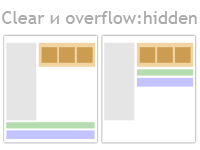 Свойство
Свойство clear со значениями left, right, both действительно очищает поток в отличие от overflow со значеним hidden, которое создаёт отдельный контекст форматирования для выбранного элемента, тем самым локализуя действие свойства float внутри элемента к которому применён.Представления (VIEW) в MySQL
10 min
В комментариях Хабра упоминались вопросы по использованию представлений. Данный топик является обзором представлений, появившихся в MySQL версии 5.0. В нем рассмотрены вопросы создания, преимущества и ограничения представлений.
Представление (VIEW) — объект базы данных, являющийся результатом выполнения запроса к базе данных, определенного с помощью оператора SELECT, в момент обращения к представлению.
Представления иногда называют «виртуальными таблицами». Такое название связано с тем, что представление доступно для пользователя как таблица, но само оно не содержит данных, а извлекает их из таблиц в момент обращения к нему. Если данные изменены в базовой таблице, то пользователь получит актуальные данные при обращении к представлению, использующему данную таблицу; кэширования результатов выборки из таблицы при работе представлений не производится. При этом, механизм кэширования запросов (query cache) работает на уровне запросов пользователя безотносительно к тому, обращается ли пользователь к таблицам или представлениям.
Что такое представление?
Представление (VIEW) — объект базы данных, являющийся результатом выполнения запроса к базе данных, определенного с помощью оператора SELECT, в момент обращения к представлению.
Представления иногда называют «виртуальными таблицами». Такое название связано с тем, что представление доступно для пользователя как таблица, но само оно не содержит данных, а извлекает их из таблиц в момент обращения к нему. Если данные изменены в базовой таблице, то пользователь получит актуальные данные при обращении к представлению, использующему данную таблицу; кэширования результатов выборки из таблицы при работе представлений не производится. При этом, механизм кэширования запросов (query cache) работает на уровне запросов пользователя безотносительно к тому, обращается ли пользователь к таблицам или представлениям.