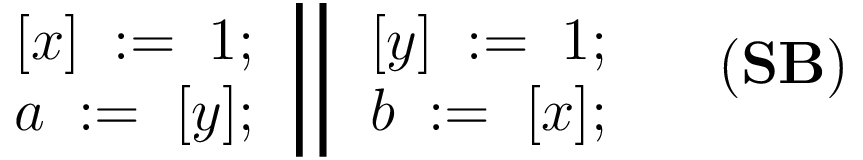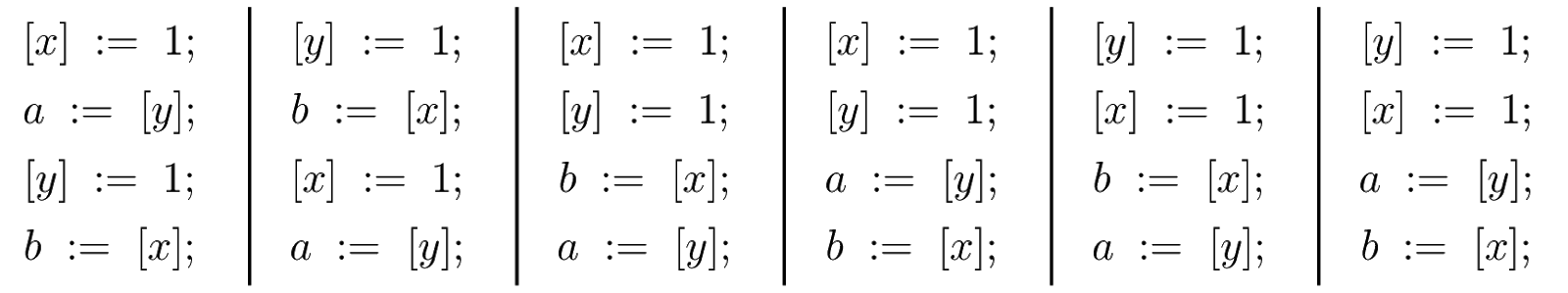Приёмы неблокирующего программирования: атомарные операции и частичные барьеры памяти
В первой статье цикла мы познакомились с простыми неблокирующими алгоритмами, а также рассмотрели отношение “happens before”, позволяющее их формализовать. Следующим шагом мы рассмотрим понятие «гонки данных» (data race), а также примитивы, которые позволяют избежать гонок данных. После этого познакомимся с атомарными примитивами, барьерами памяти, а также их использованием в механизме “seqcount”.
С барьерами памяти некоторые разработчики ядра Linux уже давно знакомы. Первый документ, содержащий что-то похожее на спецификацию гарантий, предоставляемых ядром при одновременном доступе к памяти — он так и называется: memory-barriers.txt. В этом файле описывается целый зоопарк барьеров вместе с ожидаемым поведением многопоточного кода в ядре. Также там описывается понятие «парных барьеров» (barrier pairing), что похоже на пары release-acquire операций и тоже помогает упорядочивать работу потоков.
В этой статье мы не будем закапываться так же глубоко, как memory-barriers.txt. Вместо этого мы сравним барьеры с моделью acquire и release-операций и рассмотрим, как они упрощают (или, можно сказать, делают возможной) реализацию примитива “seqcount”. К сожалению, даже если ограничиться лишь наиболее популярными применениями барьеров — это слишком обширная тема, поэтому о полных барьерах памяти мы поговорим в следующий раз.