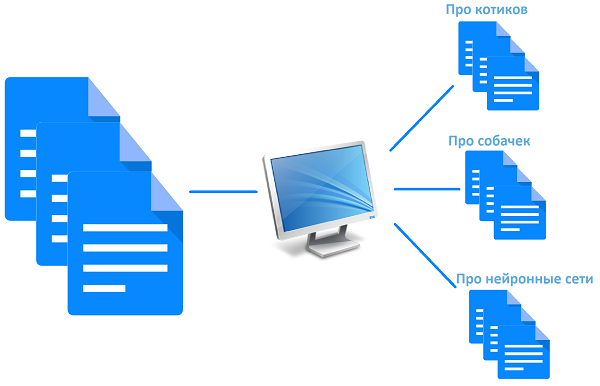
Компания Backblaze начиная с 2013 года ведет статистику эксплуатации жестких дисков в своих дата-центрах. Специалисты следят, какие диски работают без отказов и сбоев в течение какого времени. Ведется также анализ надежности HDD разных производителей. В базу данных включают дату производства диска, производителя, модель, серийный номер, статус (рабочий ли диск или умерший), а также SMART-атрибуты, которые сообщает сам диск. К концу 2017 года в базе данных накопилось около 88 миллионов объектов. Размер БД составляет 23 ГБ. Загрузить ее можно с сайта компании — вот здесь.
В новом отчете указываются данные по эксплуатации HDD за 2017 году. На момент составления документа в дата-центрах компании работало 91 305 винчестеров. Отчет можно просмотреть за разные периоды времени, включая каждый квартал по отдельности или же информацию за целый год.



 Давным-давно, когда Pentium-мы были первыми, харды гигабайтными, а видеокарты PCI-йными. Купил я как-то себе на организацию замечательную видеокарточку GeForce в красивой коробочке, где кроме собственно карточки лежали ещё очки с ЖК затворами...
Давным-давно, когда Pentium-мы были первыми, харды гигабайтными, а видеокарты PCI-йными. Купил я как-то себе на организацию замечательную видеокарточку GeForce в красивой коробочке, где кроме собственно карточки лежали ещё очки с ЖК затворами...