Разработка хранилища — дело долгое и серьезное.
Многое в жизни проекта зависит от того, насколько хорошо продумана объектная модель и структура базы на старте.
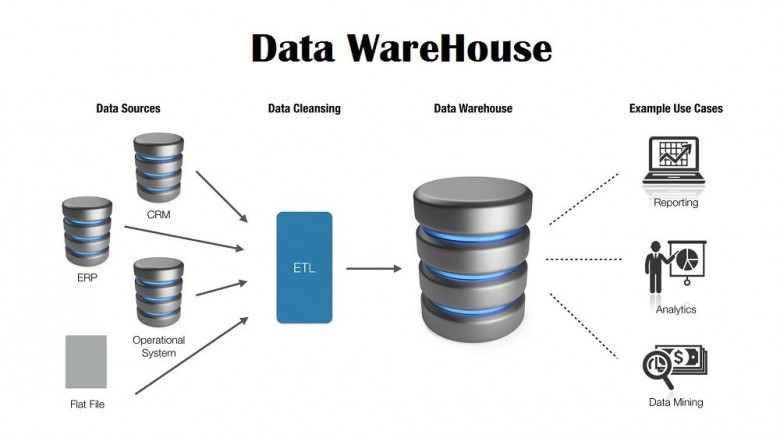
Общепринятым подходом были и остаются различные варианты сочетания схемы “звезда” с третьей нормальной формой. Как правило, по принципу: исходные данные — 3NF, витрины — звезда. Этот подход, проверенный временем и подкрепленный большим количеством исследований — первое (а иногда и единственное), что приходит в голову опытному DWH-шнику при мысли о том, как должно выглядеть аналитическое хранилище.
С другой стороны — бизнесу в целом и требованиям заказчика в частности свойственно быстро меняться, а данным — расти как “вглубь”, так и “вширь”. И вот тут проявляется основной недостаток звезды — ограниченная
гибкость.
И если в вашей тихой и уютной жизни DWH-разработчика внезапно:
- возникла задача “сделать быстро хоть что-то, а потом посмотрим”;
- появился бурно развивающийся проект, с подключением новых источников и переделкой бизнес-модели минимум раз в неделю;
- появился заказчик, который не представляет как система должна выглядеть и какие функции выполнять в конечном итоге, но готов к экспериментам и последовательному уточнению желаемого результата с последовательным же приближением к нему;
- заглянул менеджер проектов с радостной вестью: “А теперь у нас аджайл!”.
Или если вам просто интересно узнать как еще можно строить хранилища — вэлкам под кат!