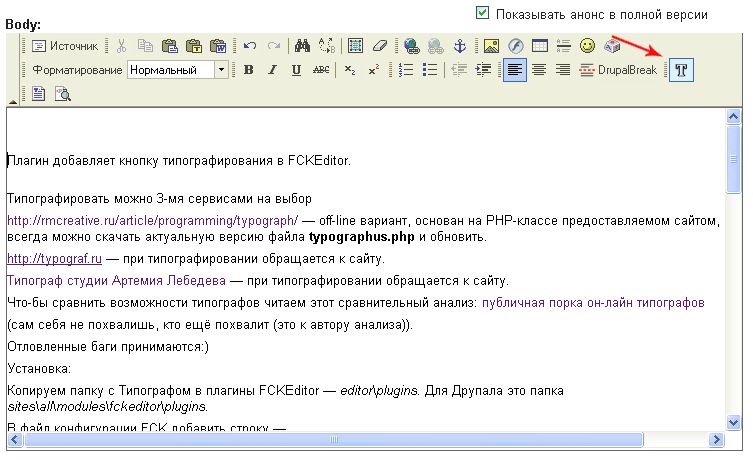
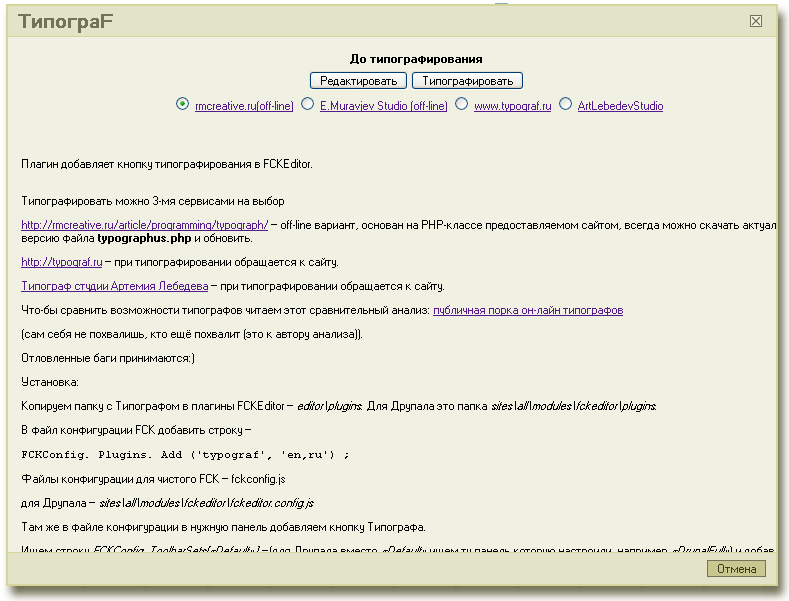
На UpStartConf – секции о рынке инвестиций и стартапов в рамках РИФа-2011 основатели Островок.ру рассказывали о том, как привлечь в Рунет мировых инвесторов.
Эксперты, инвесторы и IT-предприниматели Рунета сошлись в едином мнении, что на российском интернет-рынке нет публичных кейсов стартапов, нет обучения для начинающих веб-предпринимателей, что неблаготворно влияет на рынок. В этом посте репатрианты Кирилл Махаринский и Сергей Фаге презентуют кейс по привлечению инвестиций на примере проекта Островок.ру
Эксперты, инвесторы и IT-предприниматели Рунета сошлись в едином мнении, что на российском интернет-рынке нет публичных кейсов стартапов, нет обучения для начинающих веб-предпринимателей, что неблаготворно влияет на рынок. В этом посте репатрианты Кирилл Махаринский и Сергей Фаге презентуют кейс по привлечению инвестиций на примере проекта Островок.ру