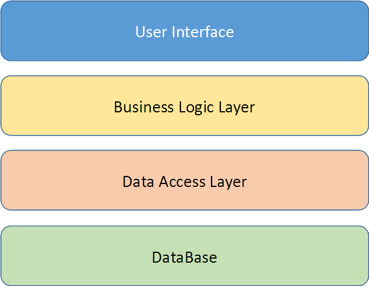
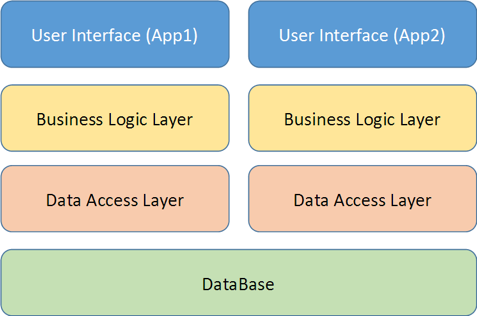
Стресс, связанный с переходом на менеджерскую роль, способен пошатнуть любые, даже самые крепкие нервы. А если ваше решение стать руководителем желанное и осознанное, то вы легко можете загнать себя в ловушку из двух стен: тревожности и перфекционизма.
Меня зовут Александр Шиндин, я — технический менеджер мобильных продуктов Kaspersky Password Manager и Kaspersky Who Calls. Я так сильно хотел проявить себя в роли руководителя, что внутренних обучающих курсов, которые дает в таких случаях компания, мне не хватало, — и лучшим дополнением к теории стали книги. Они ускорили мое погружение в мир менеджмента, помогли быть готовым к еще большему числу нестандартных ситуаций и придали уверенности в принимаемых решениях.
В этой статье поделюсь своим личным топом книг, которые оказались в свое время полезны мне и, я уверен, будут полезны и вам как будущим или начинающим техническим менеджерам.

Меня зовут Александр Шиндин, я — технический менеджер мобильных продуктов Kaspersky Password Manager и Kaspersky Who Calls. Я так сильно хотел проявить себя в роли руководителя, что внутренних обучающих курсов, которые дает в таких случаях компания, мне не хватало, — и лучшим дополнением к теории стали книги. Они ускорили мое погружение в мир менеджмента, помогли быть готовым к еще большему числу нестандартных ситуаций и придали уверенности в принимаемых решениях.
В этой статье поделюсь своим личным топом книг, которые оказались в свое время полезны мне и, я уверен, будут полезны и вам как будущим или начинающим техническим менеджерам.






 Круг задач, которые можно решить с помощью технологий ABBYY, пополнился еще одной интересной возможностью. Мы обучили свой движок работе банковского андеррайтера – человека, который из гигантского потока новостей вылавливает события о контрагентах и оценивает риски.
Круг задач, которые можно решить с помощью технологий ABBYY, пополнился еще одной интересной возможностью. Мы обучили свой движок работе банковского андеррайтера – человека, который из гигантского потока новостей вылавливает события о контрагентах и оценивает риски.