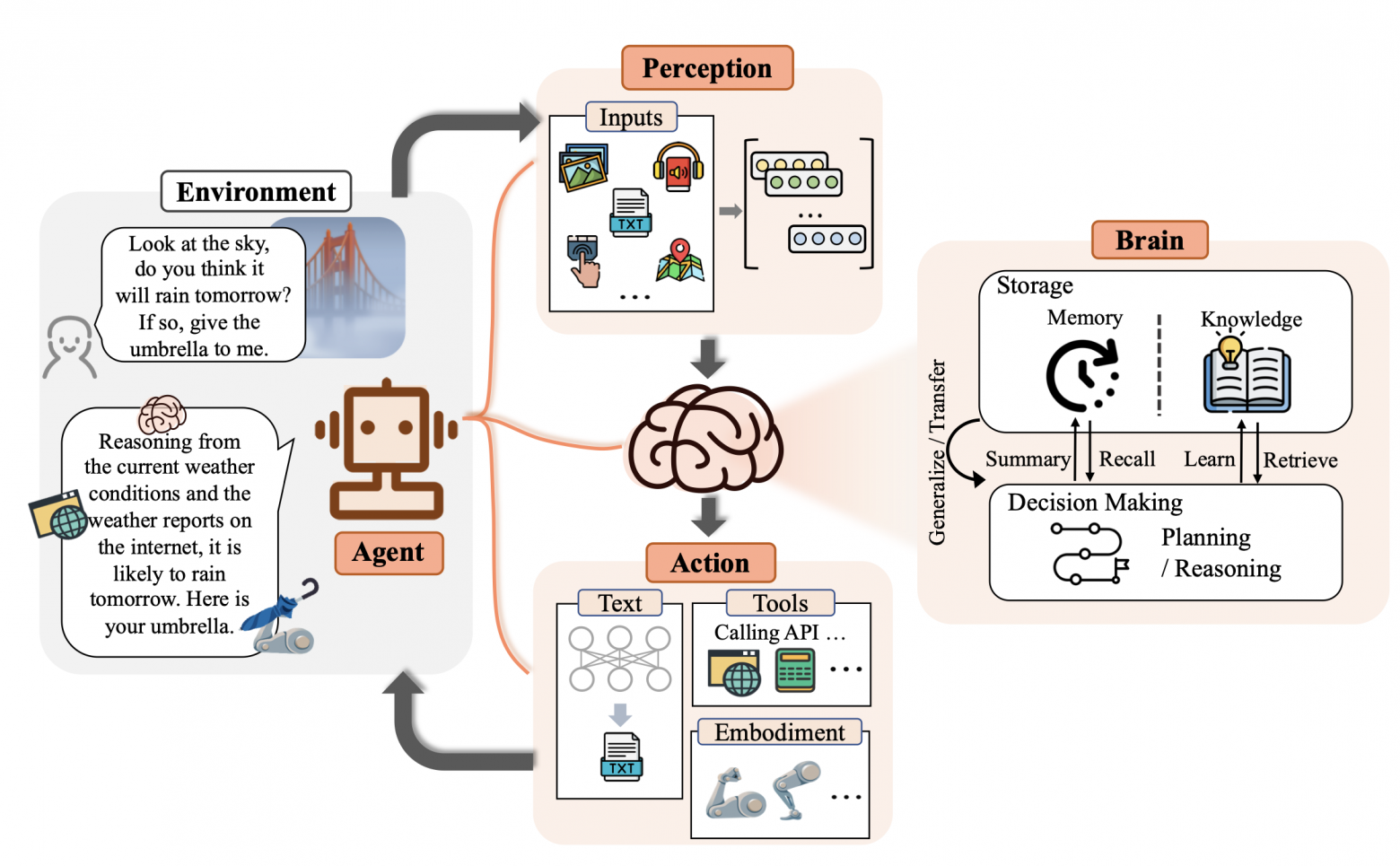
С появлением больших языковых моделей (LLM) стало казаться, что они умеют всё: от генерации кода до написания статей в научные журналы. Но, как только дело доходит до фактов, особенно актуальных и узкоспециализированных, начинаются проблемы. LLM — это не поисковики и не базы данных, знания у них статичны: что было в обучающей выборке, то модель и «знает» (да и то не всегда твёрдо). Постоянно дообучать её на актуальных данных — уже вызов. Тут на сцену выходят RAG-системы (Retrieval-Augmented Generation).
Если коротко, RAG — это способ «подкормить» LLM свежими данными: перед генерацией ответа модель получает не только сам вопрос, но и релевантные тексты, найденные внешней поисковой системе или во внутренней базе знаний. Идея звучит просто, но как понять, насколько хорошо это работает? Какие документы действительно помогли модели, а какие запутали её ещё больше? А главное — как сравнить разные RAG-системы между собой по-честному?
Оценка таких систем — нетривиальная задача. С одной стороны, нужно учитывать и качество извлечённых документов, и финальный ответ модели. С другой — важно избегать контаминации: когда модель «угадывает» правильный ответ просто потому, что уже видела его в процессе обучения. Это особенно актуально при использовании статических наборов данных вроде Natural Questions или HotpotQA: они давно «протекли» в открытые датасеты, в том числе для обучения популярных LLM.