Laplace Blur — Можно ли блюрить Лапласом вместо Гаусса, во сколько раз это быстрее, и стоит ли того потеря 1/32 точности
7 мин

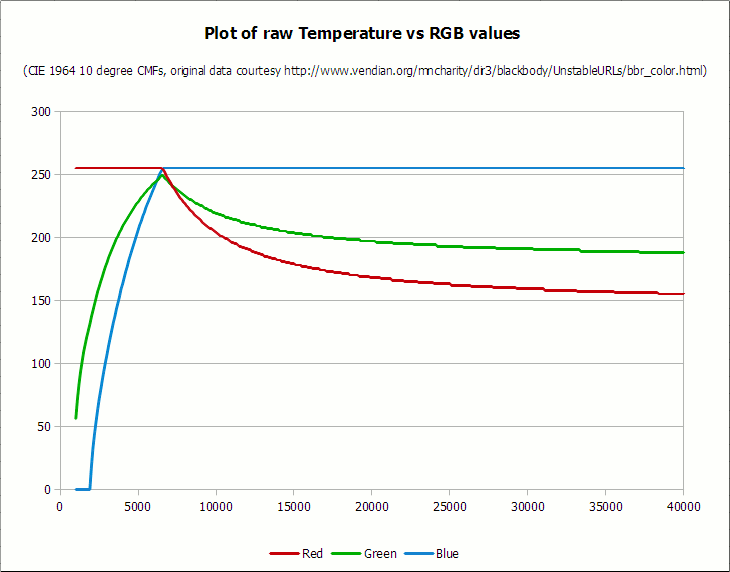
«Блюр» в простонародье — эффект размытия, в цифровой обработке изображений. Бывает очень эффектен и сам по себе, и как составляющее анимаций интерфейса, или более сложных производных эффектов (bloom/focusBlur/motionBlur). При всем этом честный блюр в лоб довольно медленен. И часто реализации встроенные в целевую платформу оставляют желать лучшего. То скорость печальна, то артефакты режут глаза. Ситуация рождает множество компромиссных реализаций, лучше или хуже подходящих для определенных условий. Оригинальная реализация с хорошим качеством достоверности и высочайшей скоростью, при этом нижайшей зависимостью от аппаратной части ждет вас под катом. Приятного аппетита!