Кадр из мультфильма «Смешарики: 132 серия (Пылесос)»
При проведении различной ad-hoc аналитики или же создания интеграций между DS решением и внешними системами очень часто приходится использовать REST API для получения данных. Ситуация, когда все помещается в один запрос — идеальна, но редка как единорог. Как правило, приходится тянуть большие объемы, тянуть по частям и в режиме многоходовок, возможно, с использованием курсоров. Внешняя система может лечь при большой нагрузке или же там включатся механизмы пропуска запросов (троттлинг). Вопросы «почему у меня не работает» и «как мне сделать, чтобы работало» возникают с завидной регулярностью.
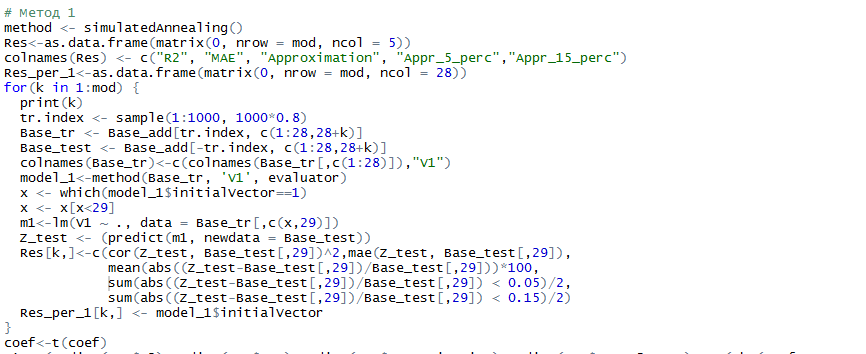
Ниже приведен блочный разбор типового скрипта для получению данных из внешней системы через REST API. Его можно рассматривать как первое приближение решения задачи подобного класса.
Является продолжением серии предыдущих публикаций.